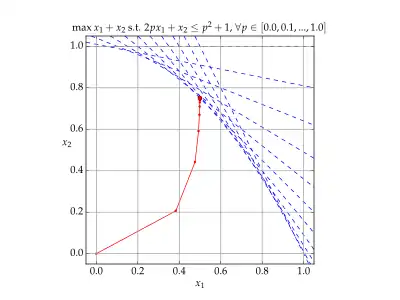
Interior-point methods (also referred to as barrier methods or IPMs) are algorithms for solving linear and non-linear convex optimization problems. IPMs combine two advantages of previously-known algorithms:
- Theoretically, their run-time is polynomial—in contrast to the simplex method, which has exponential run-time in the worst case.
- Practically, they run as fast as the simplex method—in contrast to the ellipsoid method, which has polynomial run-time in theory but is very slow in practice.
In contrast to the simplex method which traverses the boundary of the feasible region, and the ellipsoid method which bounds the feasible region from outside, an IPM reaches a best solution by traversing the interior of the feasible region—hence the name.
History
An interior point method was discovered by Soviet mathematician I. I. Dikin in 1967.[1] The method was reinvented in the U.S. in the mid-1980s. In 1984, Narendra Karmarkar developed a method for linear programming called Karmarkar's algorithm,[2] which runs in provably polynomial time ( operations on L-bit numbers, where n is the number of variables and constants), and is also very efficient in practice. Karmarkar's paper created a surge of interest in interior point methods. Two years later, James Renegar invented the first path-following interior-point method, with run-time . The method was later extended from linear to convex optimization problems, based on a self-concordant barrier function used to encode the convex set.[3]


Any convex optimization problem can be transformed into minimizing (or maximizing) a linear function over a convex set by converting to the epigraph form.[4] The idea of encoding the feasible set using a barrier and designing barrier methods was studied by Anthony V. Fiacco, Garth P. McCormick, and others in the early 1960s. These ideas were mainly developed for general nonlinear programming, but they were later abandoned due to the presence of more competitive methods for this class of problems (e.g. sequential quadratic programming).
Yurii Nesterov and Arkadi Nemirovski came up with a special class of such barriers that can be used to encode any convex set. They guarantee that the number of iterations of the algorithm is bounded by a polynomial in the dimension and accuracy of the solution.[5][3]
The class of primal-dual path-following interior-point methods is considered the most successful. Mehrotra's predictor–corrector algorithm provides the basis for most implementations of this class of methods.[6]
Definitions
We are given a convex program of the form:

where f and the gi are convex functions and G is a convex set. Without loss of generality, we can assume that the objective f is a linear function. We assume that the constraint functions belong to some family (e.g. quadratic functions), so that the program can be represented by a finite vector of coefficients (e.g. the coefficients to the quadratic functions). The dimension of this coefficient vector is called the size of the program. A numerical solver for a given family of programs is an algorithm that, given the coefficient vector, generates a sequence of approximate solutions xt for t=1,2,..., using finitely many arithmetic operations. A numerical solver is called convergent if, for any progarm from the family and any positive ε>0, there is some T (which may depend on the program and on ε) such that, for any t>T, the approximate solution xt is ε-approximate, that is:
f(x) - f* ≤ ε
gi(x) ≤ ε for i in 1,...,m,
x in G,
where f* is the optimal solution. A solver is called polynomial if the total number of arithmetic operations in the first T steps is at most
poly(problem-size) * log(V/ε),
where V represents e.g. the largest value in the coefficient vector. In other words, V/ε is the "relative accuracy" of the solution - the accuracy w.r.t. the largest coefficient. log(V/ε) represents the number of "accuracy digits". Therefore, a solver is 'polynomial' if each additional digit of accuracy requires a number of operations that is polynomial in the problem size.
Types
Types of interior point methods include:
- Potential reduction methods: Karmarkar's algorithm was the first one.
- Path-following methods: the algorithms of James Renegar[7] and Clovis Gonzaga[8] were the first ones.
- Primal-dual methods.
Path-following methods
Idea
Given a convex optimization program (P) with constraints, we can convert it to an unconstrained program by adding a barrier function. Specifically, let b be a smooth convex function, defined in the interior of the feasible region G, such that for any sequence {xj in interior(G)} whose limit is on the boundary of G: . We also assume that b is non-degenerate, that is: is positive definite for all x in interior(G). Now, consider the family of programs:


(Pt) minimize t * f(x) + b(x)
Technically the program is restricted, since b is defined only in the interior of G. But practically, it is possible to solve it as an unconstrained program, since any solver trying to minimize the function will not approach the boundary, where b approaches infinity. Therefore, (Pt) has a unique solution - denote it by x*(t). The function x* is a continuous function of t, which is called the path. All limit points of x*, as t approaches infinity, are optimal solutions of the original program (P).
A path-following method is a method of tracking the function x* along a certain increasing sequence t1,t2,..., that is: computing a good-enough approximation xi to the point x*(ti), such that the difference xi - x*(ti) approaches 0 as i approaches infinity; then the sequence xi approaches the optimal solution of (P). This requires to specify three things:
- The barrier function b(x).
- A policy for determining the penalty parameters ti.
- The unconstrained-optimization solver used to solve (Pi) and find xi, such as Newton's method. Note that we can use each xi as a starting-point for solving the next problem (Pi+1).
The main challenge in proving that the method is polytime is that, as the penalty parameter grows, the solution gets near the boundary, and the function becomes steeper. The run-time of solvers such as Newton's method becomes longer, and it is hard to prove that the total runtime is polynomial.
Renegar[7] and Gonzaga[8] proved that a specific instance of a path-following method is polytime:
- The constraints (and the objective) are linear functions;
- The barrier function is logarithmic: b(x) := - sumj log(-gj(x)).
- The formula for updating the penalty parameter t is: ti+1 = (1+0.001/sqrt(m))*ti, where m is the number of inequality constraints;
- The solver is Newton's method, and a single step of Newton is done for each single step in t.
They proved that, in this case, the difference xi - x*(ti) remains at most 0.01, and f(xi) - f* is at most 2*m/ti. Thus, the solution accuracy is proportional to 1/ti, so to add a single accuracy-digit, it is suffiicent to multiply ti by 2 (or any other constant factor), which requires O(sqrt(m)) Newton steps. Since each Newton step takes O(m n2) operations, the total complexity is O(m3/2 n2) operations for accuracy digit.
Yuri Nesterov extended the idea from linear to non-linear programs. He noted that the main property of the logarithmic barrier, used in the above proofs, is that it is self-concordant with a finite barrier parameter. Therefore, many other classes of convex programs can be solved in polytime using a path-following method, if we can find a suitable self-concordant barrier function for their feasible region.[3]: Sec.1
Details
We are given a convex optimization problem (P) in "standard form":
minimize cTx s.t. x in G,
where G is convex and closed. We can also assume that G is bounded (otherwise, we can add a constraint |x|≤R for some sufficiently large R).[3]: Sec.4
To use the interior-point method, we need a self-concordant barrier for G. Let b be an M-self-concordant barrier for G, where M≥1 is the self-concordance parameter. We assume that we can compute efficiently the value of b, its gradient, and its Hessian, for every point x in the interior of G.
For every t>0, we define the penalized objective ft(x) := cTx + b(x), We define the path of minimizers by: x*(t) := arg min ft(x). We apporimate this path along an increasing sequence ti. The sequence is initialized by a certain non-trivial two-phase initialization procedure. Then, it is updated according to the following rule (where r>0 is a parameter called the penalty rate):
.

For each ti, we find an approximate minimum of fti, denoted by xi. The approximate minimum is chosen to satisfy the following "closeness condition" (where L is the path tolerance):
.
![{\displaystyle {\sqrt {[\nabla _{x}f_{t}(x_{i})]^{T}[\nabla _{x}^{2}f_{t}(x_{i})]^{-1}[\nabla _{x}f_{t}(x_{i})]}}\leq L}](../I/f1c487615f788974227a6e9b97a12c1b9ba72038.svg)
To find xi+1, we start with xi and apply the damped Newton method. We apply several steps of this method, until the above "closeness relation" is satisfied. The first point that satisfies this relation is denoted by xi+1.[3]: Sec.4
Convergence and complexity
The convergence rate of the method is given by the following formula, for every i:[3]: Prop.4.4.1
![{\displaystyle c^{T}x_{i}-c^{*}\leq {\frac {2M}{t_{0}}}\left[1+{\frac {r}{\sqrt {M}}}\right]^{-i}}](../I/07fd98f60a15cc1d4b1ef4c013ac728a905cf5f2.svg)
The number of Newton steps required to go from xi to xi+1 is at most a fixed number, that depends only on r and L. In particular, the total number of Newton steps required to find an ε-approximate solution (i.e., finding x in G such that cTx - c* ≤ ε) is at most:[3]: Thm.4.4.1

where the constant factor O(1) depends only on r and L. The number of Newton steps required for the two-step initialization procedure is at most:[3]: Thm.4.5.1

where the constant factor O(1) depends only on r and L, and , and is some point in the interior of G. Overall, the overall Newton complexity of finding an ε-approximate solution is at most


, where V is some problem-dependent constant: .


Each Newton step takes O(n3) arithmetic operations.
Practical considerations
The theoretic guarantees assume that the penalty parameter is increased at the rate , so the number of required Newton steps is . In practice, it is possible to increase the penalty parameter much faster; these are called long step techniques. They enable to solve problems with 20-40 Newton steps, regardless of the problem size.[3]: Sec.4.6


Potential-reduction methods
Potential-reduction methods are elaborated in.[3]: Sec.5 For potential-reduction methods, the problem is presented in the conic form:
minimize cTx s.t. x in {b+L} ᚢ K,
where b is a vector in Rn, L is a linear subspace in Rn (so b+L is an affine plane), and K is a closed pointed convex cone with a nonempty interior. Every convex program can be converted to the conic form.
Primal-dual methods
The primal-dual method's idea is easy to demonstrate for constrained nonlinear optimization.[9][10] For simplicity, consider the following nonlinear optimization problem with inequality constraints:

This inequality-constrained optimization problem is solved by converting it into an unconstrained objective function whose minimum we hope to find efficiently. Specifically, the logarithmic barrier function associated with (1) is

Here is a small positive scalar, sometimes called the "barrier parameter". As converges to zero the minimum of should converge to a solution of (1).


The gradient of a differentiable function is denoted . The gradient of the barrier function is



In addition to the original ("primal") variable we introduce a Lagrange multiplier-inspired dual variable



Equation (4) is sometimes called the "perturbed complementarity" condition, for its resemblance to "complementary slackness" in KKT conditions.
We try to find those for which the gradient of the barrier function is zero.

Substituting from (4) into (3), we get an equation for the gradient:


where the matrix is the Jacobian of the constraints .


The intuition behind (5) is that the gradient of should lie in the subspace spanned by the constraints' gradients. The "perturbed complementarity" with small (4) can be understood as the condition that the solution should either lie near the boundary , or that the projection of the gradient on the constraint component normal should be almost zero.




Let be the search direction for iteratively updating . Applying Newton's method to (4) and (5), we get an equation for :



where is the Hessian matrix of , is a diagonal matrix of , and is the diagonal matrix of .




Because of (1), (4) the condition

should be enforced at each step. This can be done by choosing appropriate :


Special cases
Here are some special cases of convex programs, that can be solved efficiently by interior-point methods.[3]: Sec.10
- Linear programming: given a program of the form: minimize cTx s.t. Ax ≤ b, we can apply path-following methods with the barrier . It is a self-concordant barrier with parameter M=m (the number of constraints). Therefore, the number of required Newtoמ steps for the path-following method is O(mn2), and the total runtime complexity is O(m3/2 n2).
- Quadratically constrained quadratic programing: given a program of the form: minimize dTx s.t. fj(x) := xT Aj x + bjTx + cj ≤ 0 for all j in 1,...,m, where all matrices Aj are positive-semidefinite, we can apply path-following methods with the barrier . It is a self-concordant barrier with parameter M=m. The Newton complexity is O((m+n)n2), and the total runtime complexity is O(m1/2 (m+n) n2).
- Approximation in Lp norm: we are given a problem of the form minimize sumj |vj-ujTx|p, where 1<p<∞, uj are vectors and vj are scalars. After converting to the standard form, we can apply path-following methods with a self-concordant barrier with parameter M=4m. The Newton complexity is O((m+n)n2), and the total runtime complexity is O(m1/2 (m+n) n2).
- Geometric programming: we are given a problem with objective function f0(x)=sumi ci0 exp(aiTx), and constraints fj(x)=sumi cij exp(aiTx) ≤ dj for j in 1,...,m and i in 1,...,k. There is a self-concordant barrier with parameter 2k+m. The path-following method has Newton complexity O(mk2+k3+n3) and total complexity O((k+m)1/2[mk2+k3+n3]).
- Semidefinite programming.[3]: Sec.11


See also
References
- ↑ Dikin, I.I. (1967). "Iterative solution of problems of linear and quadratic programming". Dokl. Akad. Nauk SSSR. 174 (1): 747–748.
- ↑ Karmarkar, N. (1984). "A new polynomial-time algorithm for linear programming" (PDF). Proceedings of the sixteenth annual ACM symposium on Theory of computing – STOC '84. p. 302. doi:10.1145/800057.808695. ISBN 0-89791-133-4. Archived from the original (PDF) on 28 December 2013.
- 1 2 3 4 5 6 7 8 9 10 11 12 Arkadi Nemirovsky (2004). Interior point polynomial-time methods in convex programming.
- ↑ Boyd, Stephen; Vandenberghe, Lieven (2004). Convex Optimization. Cambridge: Cambridge University Press. p. 143. ISBN 978-0-521-83378-3. MR 2061575.
- ↑ Wright, Margaret H. (2004). "The interior-point revolution in optimization: History, recent developments, and lasting consequences". Bulletin of the American Mathematical Society. 42: 39–57. doi:10.1090/S0273-0979-04-01040-7. MR 2115066.
- ↑ Potra, Florian A.; Stephen J. Wright (2000). "Interior-point methods". Journal of Computational and Applied Mathematics. 124 (1–2): 281–302. doi:10.1016/S0377-0427(00)00433-7.
- 1 2 Renegar, James (1 January 1988). "A polynomial-time algorithm, based on Newton's method, for linear programming". Mathematical Programming. 40 (1): 59–93. doi:10.1007/BF01580724. ISSN 1436-4646.
- 1 2 Gonzaga, Clovis C. (1989), Megiddo, Nimrod (ed.), "An Algorithm for Solving Linear Programming Problems in O(n3L) Operations", Progress in Mathematical Programming: Interior-Point and Related Methods, New York, NY: Springer, pp. 1–28, doi:10.1007/978-1-4613-9617-8_1, ISBN 978-1-4613-9617-8, retrieved 22 November 2023
- ↑ Mehrotra, Sanjay (1992). "On the Implementation of a Primal-Dual Interior Point Method". SIAM Journal on Optimization. 2 (4): 575–601. doi:10.1137/0802028.
- ↑ Wright, Stephen (1997). Primal-Dual Interior-Point Methods. Philadelphia, PA: SIAM. ISBN 978-0-89871-382-4.
- Bonnans, J. Frédéric; Gilbert, J. Charles; Lemaréchal, Claude; Sagastizábal, Claudia A. (2006). Numerical optimization: Theoretical and practical aspects. Universitext (Second revised ed. of translation of 1997 French ed.). Berlin: Springer-Verlag. pp. xiv+490. doi:10.1007/978-3-540-35447-5. ISBN 978-3-540-35445-1. MR 2265882.
- Nocedal, Jorge; Stephen Wright (1999). Numerical Optimization. New York, NY: Springer. ISBN 978-0-387-98793-4.
- Press, WH; Teukolsky, SA; Vetterling, WT; Flannery, BP (2007). "Section 10.11. Linear Programming: Interior-Point Methods". Numerical Recipes: The Art of Scientific Computing (3rd ed.). New York: Cambridge University Press. ISBN 978-0-521-88068-8.
|  Optimization computes maxima and minima. | |||||||||||||||||
| ||||||||||||||||||
| ||||||||||||||||||
| ||||||||||||||||||