| Chinese characters | |
|---|---|
| Script type | Logographic
|
Time period | c. 13th century BCE – present |
| Direction |
|
| Languages | |
| Related scripts | |
Parent systems | Oracle bone script
|
Child systems | |
| ISO 15924 | |
| ISO 15924 | Hani (500), Han (Hanzi, Kanji, Hanja) |
| Unicode | |
Unicode alias | Han |
| |
| Chinese characters | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Chinese name | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Simplified Chinese | 汉字 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Traditional Chinese | 漢字 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Literal meaning | "Han characters" | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Vietnamese name | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Vietnamese alphabet | chữ Hán chữ Nho Hán tự | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Hán-Nôm | 𡨸漢 𡨸儒 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Chữ Hán | 漢字 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Thai name | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Thai | อักษรจีน | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Zhuang name | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Zhuang |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Korean name | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Hangul | 한자 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Hanja | 漢字 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Japanese name | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Kanji | 漢字 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Hiragana | かんじ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Khmer name | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Khmer | តួអក្សរចិន | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
Chinese characters (traditional Chinese and Japanese: 漢字; simplified Chinese: 汉字; pinyin: hànzì; Cantonese Jyutping: hon3 zi6; Wade–Giles: han4 tzŭ4; rōmaji: kanji; "Han characters") are logograms used to write the Chinese languages and several other languages historically influenced by Chinese culture.[2][3]: 82 Chinese characters represent one of the four independent inventions of writing in human history to be universally accepted by scholars,[4][lower-alpha 2] and are the only one of these to be continuously used since its invention, with a documented history spanning more than three millennia.[5] Over this span, the function and style of characters has evolved greatly. Most recently, countries using Chinese characters have standardised their forms and pronunciations. Broadly, simplified characters are used in mainland China, Singapore, and Malaysia, while traditional characters are used in Taiwan, Hong Kong, and Macau.[6]
Chinese characters were historically adapted to write other languages spoken within the Sinosphere. Chinese characters in Japanese, Korean, and Vietnamese are known as kanji, hanja, and chữ Hán respectively. Of these, each also created their own characters for their internal use. These languages generally function very differently from Chinese, and belong to their own independent language families. In part due to this difference, Korean and Vietnamese are now written almost exclusively with alphabets designed to replace Chinese characters. This leaves Japanese as the sole major language unrelated to Chinese still written with Chinese characters.
Unlike in phonetic writing systems, where individual letters roughly correspond to phonemes, the Chinese writing system associates each logogram with a syllable. In fact, written characters, syllables, and morphemes—the basic units of meaning in a language—largely correspond one-to-one with one another in Chinese languages.[7][lower-alpha 3][lower-alpha 4] However, written Chinese is not ideographic—characters fundamentally correspond to spoken syllables, not to the abstracted ideas themselves.
To a higher degree than most major languages, modern spoken Chinese has many homophones: the same spoken syllable can be represented by one of several different characters depending on context. Additionally, a particular character may have a range of different meanings; different readings of the same character may have different pronunciations and even etymologies. In Standard Chinese, one-fifth of the 2,400 most common characters have several pronunciations.[lower-alpha 5]
Classification
Chinese characters are used within several distinct writing systems that have developed throughout history, which may also include other elements such as punctuation, as well as rules with which characters are used. Numerous models attempting to explain how Chinese characters work to encode language have been presented by scholars. As models reflecting human language, any rules or categories for characters are imperfect. Broadly, in order to create meaning Chinese characters make use of the sounds of spoken language, the abstract ideas underpinning words, and graphical shape together, such that each dimension reinforces the others.
Traditional Shuowen Jiezi scheme
The Shuowen Jiezi was a hugely influential character dictionary written by the scholar Xu Shen c. 120 CE. In the dictionary's postface, Xu analyses what he sees as all the methods by which characters are created. This work introduced a categorisation scheme which would later become known as the liùshū (六書; 六书; 'six writings'). Mature formulations of this scheme stated that every character belonged to one of six categories, each mentioned with varying emphasis in the Shuowen Jiezi. For nearly two millennia afterwards, this framework would serve as the traditional lens through which characters were analysed throughout the Sinosphere.[10] Xu based most of his analysis on examples of Qin seal script that were written down several centuries before his time—these were usually the oldest forms available to him, but Xu stated that he was aware of the existence of even older forms.[11]
Modern scholars agree that the theory presented in the Shuowen Jiezi is problematic, failing to fully capture the nature of Chinese writing, both in the present, as well as at the time Xu was writing.[12][13] However, the model has proven resilient and pervasive; it continues to serve as a guide for those studying writing systems that use Chinese characters. One of the most important features of the Shuowen Jiezi was its grouping of characters by radical: a component within a character that is generally considered to be of particular import. The Shuowen Jiezi recognised over 500 radicals—this number would be reduced substantially in future dictionaries, but the concept itself would remain ubiquitous.
Pictograms



Presented as a fundamental class upon which the rest of the writing system depends, a relatively small number of characters are pictograms, representational pictures of physical objects.[14][15] In practice, their forms are highly stylised and simplified from centuries of iteration: examples include 日 ('Sun'), 月 ('moon'), and 木 ('tree').[upper-alpha 1] Xu Shen placed approximately 4% of all characters into this category.
Over time, pictograms became increasingly stylised, simplified, and standardised, in order to make them easier to write. As character forms developed, distinct depictions of various physical objects within pictographs became reduced to instances of a single written component.[16][17] As such, what a pictogram is depicting is often not immediately evident. For example, within a given character the radical ⼝ 'MOUTH' often carries a meaning related to mouths, but within 高 ('tall')—a pictogram of a tall building—it instead depicts a window, ultimately lending to the character's meaning of 'tallness'. In another instance, the same 'mouth' radical depicts the lip of a vessel in the modern form of the pictogram 畐 ('full').[upper-alpha 2]
Pictograms have often been extended from their original concrete meanings to take on additional layers of metaphor and synecdoche, which sometimes even displace the pictogram's original, literal meaning. Over time, this process sometimes creates excess ambiguity between graphically or phonetically similar characters, which is then usually resolved through adding additional components to disambiguate the characters in question. This can result in new pictograms, but usually results in other character types instead.[18]
Simple ideograms
Also called simple indicatives, characters in this small category visually depict abstract concepts that lack corresponding physical forms, but nonetheless can be gestured towards intuitively.[15] Examples include 上 ('up') and 下 ('down')—originally written as dots above and below a line, later evolving into their present forms which are less potentially ambiguous in context[19]—凸 ('convex'), 凹 ('concave'), and 平 ('flat and level'). Though few in number and limited in their scope, pictograms and ideograms form the basis on which more complex characters are derived.
Compound ideographs
Also translated as logical aggregates or associative idea characters, characters in this class are formed by combining two or more pictographs or ideographs to suggest a new, synthetic meaning. The canonical example is 明 ('bright'), often interpreted as the juxtaposition of the two brightest objects in the sky: 日 ('sun'), and 月 ('moon'), together expressing their shared quality of brightness. Though the historicity of this particular etymology has been contested in recent scholarship, it is definitively a canonical reading: for example, the common compound word 明白 means 'understanding', touching on the derived association of 明 with 'illumination'. The addition of the abbreviated 艹 'GRASS' radical on top results in the compound ideograph 萌 ('to sprout'), alluding to the heliotropic behaviour of plant life. Other commonly cited examples include 休 ('rest'), composed of pictographs ⼈ 'MAN' and ⽊ 'TREE', and 好 ('good'), composed of ⼥ 'WOMAN' and ⼦ 'CHILD'.[upper-alpha 3]

Xu Shen placed approximately 13% of characters in this category, but many of his examples are now believed to be phono-semantic compounds, whose origin has been obscured by subsequent changes in their form.[20] Peter Boodberg and William Boltz go so far as to deny that any of the compound characters devised in ancient times were of this type, maintaining that now-lost "secondary readings" are responsible for the apparent absence of phonetic indicators,[21] but their arguments have been rejected by other scholars.[22]
In contrast, associative compound characters are common among kokuji, kanji originally coined in Japan. An example of a modern compound ideograph in the Chinese language is 砼 ('concrete'), combining the ⼈ 'MAN', ⼯ 'WORK', and ⽯ 'STONE' radicals.[upper-alpha 4]
Phonetic loans
A pivotal development in the history of Chinese writing was the initial application of the rebus principle, or phonetic borrowing, in which an existing character could be used to represent a totally unrelated word with a similar pronunciation.[23] In logographies, the use of rebus as a device represents a stage at which the writing system may begin to acquire a deeper phonetic dimension, and thus becoming more expressive as a whole.[24] Chinese characters used purely for their sound values are attested in manuscripts dating to the Eastern Zhou period, with swapping between different characters to represent the same spoken word sometimes occurring within a span of only a handful of lines: for example, 氏 (zhī) is used to write 是 (shì) and vice versa, and likewise with 勺 (sháo) for 趙 (zhào). At the time of writing, these characters were either homophonous, or nearly so.[25]
Sometimes the old meaning of a borrowed character was subsequently lost completely, as with characters such as 自 (zì), which has lost its original meaning of 'nose' completely, and now exclusively has the meaning of 'oneself', or 萬 (wàn), which originally meant 'scorpion', but is now used only to mean the number 'ten thousand'.
When transcribing words of foreign origin, such as contemporary non-Chinese names, as well as the Buddhist terminology introduced to China in antiquity, Chinese characters are used for their phonetic value, in a rebus-like fashion. For example, in the name 罗马尼亚; 羅馬尼亞 (Luómǎníyà; 'Romania'), each character is only used for its sound value, and does not provide any particular meaning.[26] This usage is similar to that of Japanese katakana and hiragana, although these syllabaries use a special set of simplified forms derived from Chinese characters, in order to clarify their purely phonetic role. Use of the rebus principle has also been observed with names written in other logographies, including both Egyptian hieroglyphs and the Maya script.[27] However, the barrier between a character's pronunciation and meaning is never total: when transcribing into Chinese, phonetic characters are often chosen deliberately as to create certain connotations. This is regularly done with corporate brand names: for example, Coca-Cola's Chinese name is 可口可乐; 可口可樂 (Kěkǒu Kělè; 'the mouth can be happy'), with the phonetic characters selected as to possess a plausible meaning of "delicious and enjoyable".[26][27]
Phono-semantic compounds
Also known as semantic-phonetic compounds or picto-phonetic compounds, these characters are composed of at least two parts: the semantic component that suggests the general meaning of the compound, and the phonetic component that gives a hint as to the compound's pronunciation. Phono-semantic compounds are by far the largest class of characters within the traditional six-fold schema.[28] In most cases, the semantic component is also the radical under which the character is categorised in dictionaries. Variously, the phonetic component of a compounds may be selected as to contribute an additional layer of meaning to the compound: as a result, determining whether a given character is a phono-semantic compound or a purely ideographic compound is often non-trivial.[14]
Examples of phono-semantic compounds include 河 (hé; 'river'), 湖 (hú; 'lake'), 流 (liú; 'stream'), 沖 (chōng; 'surge'), and 滑 (huá; 'slippery'). On the left-hand side of each, these characters have three short strokes: 氵, a reduced form of the ⽔ 'WATER' radical. In these cases, this indicates to the reader that the meaning of each character is related on some level to the concept of "water". On the other side of each character is the phonetic component: 湖 (hú) is pronounced identically to 胡 (hú) in Standard Chinese, 河 (hé) is pronounced similarly to 可 (kě), and 沖 (chōng) is pronounced similarly to 中 (zhōng).[lower-alpha 6] While the discrepancies in these examples are rather tame, over time the accumulation of sound changes often result in a given character's original composition seeming totally arbitrary to a modern reader.
Generally, while the phonetic components within some compounds do relate a precise pronunciation, most may only provide an approximation, even before the emergence of any later sound changes. Some may only share the initial or final sounds of their phonetic components.[31] With those changes, some characters may eventually seem totally unrelated to their phonetic component in their sounds. Sometimes, this actually turns out to be an accurate assessment, when dealing with characters that have undergone re-borrowing or orthographic merger with another phonetically distinct character, such that the new form is not actually associated with its original pronunciation. However, a divergence simply due to the sum total of centuries of phonetic change in the spoken language is equally as common. The table below lists characters that each use 也 for their phonetic part—save the final one, which uses a previous character in the list—it is apparent that none of them share its modern pronunciation. The Old Chinese pronunciation of 也 has been reconstructed by Baxter and Sagart (2014) as /*lAjʔ/, similar to that for each compound.[32] The table illustrates numerous sound changes that have taken place since the Shang and Zhou dynasties, the time during which most of the characters below first entered the lexicon. For a modern reader the resulting drift is dramatic, to the point where the phonetic component in each character no longer provides any hint whatsoever as to its pronunciation.[33]
| Char. | Gloss[lower-alpha 7] | Component | OC[lower-greek 1] | MC[lower-greek 2] | Modern[lower-greek 3] | |||
|---|---|---|---|---|---|---|---|---|
| Sem. | Phon. | Mandarin | Cantonese | Japanese | ||||
| 也 | PTC | —[lower-alpha 8] | /*lAjʔ/ | yaeX | yě [jè] | jaa5 [jaː˩˧] | ya [ja̠] | |
| 池 | 'pool' | 水 (氵) 'water' |
也 /*lAjʔ/ |
/*Cə.lraj/ | drje | chí [ʈʂʰǐ] | ci4 [tsʰiː˩] | chi [tɕi] |
| 馳 | 'gallop' | 馬 'horse' |
/*[l]raj/ | |||||
| 弛 | 'loosen' | 弓 'bow' |
/*l̥ajʔ/ | syeX | chí [ʈʂʰǐ] shǐ [ʂì] |
ci4 [tsʰiː˩] | chi [tɕi] shi [ɕi] | |
| 施 | 'set up' | 㫃 'flag' |
/*l̥aj/ | sye | shī [ʂí] | si1 [siː˥] | se [se̞] shi [ɕi] | |
| 地 | 'ground' | 土 'earth' |
/*[l]ˤej-s/ | dijH | dì [tî] | dei6 [tei˨] | ji [dʑi] chi [tɕi] | |
| 他 㐌 |
3-PR | 人 (亻, 𠂉) 'person' |
/*l̥ˤaj/ | tha | tā [tʰá] | taa1 [tʰaː˥] | ta [ta̠] | |
| 她 | 3-PR-F | 女 'female' |
—[lower-alpha 9] | —[lower-alpha 9] | ||||
| 拖 | 'drag' | 手 (扌) 'hand' | 㐌 /*l̥ˤaj/ |
/*l̥ˤaj/ | thaH | tuō [tʰwó] | to1 [tʰɔː˥] | ta [ta̠] da [da̠] |
Writing during the first century, Xu Shen placed approximately 82% of characters into this category. Within the 18th-century Kangxi Dictionary, the figure is closer to 90%, pointing to the historical proficiency of this technique in extending the Chinese vocabulary.[34] The principle later saw direct adoption in the creation of new chữ Nôm characters in Vietnam.
This method is still used to form new characters: for example 鈈 (bù; 'plutonium') is the ⾦ 'GOLD' radical plus the phonetic 不 (bù)—described in Chinese as "不 gives sound, 金 gives meaning". Many Chinese names for chemical elements and other characters related to chemistry were formed in this way. In fact, it is possible to tell just by glancing at a Chinese periodic table which elements are metals (⾦ 'GOLD'), solid non-metals (⽯ 'STONE'), liquids (氵 'WATER'), or gases (⽓ 'STEAM') at standard temperature and pressure.
Occasionally, a disyllabic word is written with two characters that contain the same radical, as in 蝴蝶 ('butterfly'), where both characters have the ⾍ 'INSECT' radical. A notable example regards the name for the pipa, a type of lute. The instrument's name 枇杷 was originally shared with one for the loquat,[lower-alpha 10] which has a shape reminiscent of the instrument. The name for the instrument was originally written with the 扌 'HAND' radical as 批把, referring to the upward and downward strokes made when playing the instrument. The name for the fruit was later changed to its present 枇杷, with the ⽊ 'TREE' radical; the name for the instrument became 琵琶, with 珡 ('guqin') added to both characters.[upper-alpha 5] In other cases, characters within a compound word sharing a radical may be a coincidence without any particular meaning.
Derivative cognates
The smallest category of characters is also the least understood.[35] In the postface to the Shuowen Jiezi, Xu Shen gave the example pair of 考 (kǎo; 'to verify') and 老 (lǎo; 'old'), which have similar OC pronunciations of /*khuʔ/ and /*C-ruʔ/ respectively,[36][lower-greek 4] suggests they may once have been the same word meaning 'elderly person', only to later lexicalise into two separate words. However, a specific term for the character class does not appear in the actual body of the dictionary, and it is often omitted from modern classification systems.[37]
Contemporary schemes
The traditional Shuowen Jiezi schema presupposes either a phonetic or semantic purpose for every character component.[38][39] More recently, using the lens of modern semiotics, many components have been identified as not functioning in either role: they are purely signs, or "pure forms". Basic examples of pure form characters are found with the numerals beyond four, e.g. 五; 'five' and 八; 'eight', whose forms do not give visual hints to the quantities they represent.[40] From this structural point of view, various systems have been proposed by modern scholars, with a straightforward example being seven categories of:[41][42]
- Semantic characters made of only semantic components,
- Phonetic characters made of only phonetic components,
- Pure form characters made of only pure form components,
- Semantic–phonetic characters made of both semantic and phonetic components,
- Semantic–form characters made of semantic and pure form components,
- Phonetic–form characters made of phonetic and pure form components, and
- Semantic–phonetic–form characters with all three component types.
According to Yang,[43] of the 3,500 frequently used characters in contemporary Standard Chinese, semantic characters are the rarest, accounting for about 5% of the lexicon, followed by pure form characters with 18%, and semantic–form and phonetic–form together accounting for 19%, with the remaining 58% being semantic–phonetic characters—loosely analogous to the traditional category of phono-semantic compounds.
Words
In Chinese, there is a distinction between characters and words. In modern Chinese varieties, most words are compounds written with two or more characters.[44] Written Chinese first emerged during the stage of the spoken language's development known as Old Chinese. In most cases, each Chinese character corresponds to a morpheme that was originally an independent word in Old Chinese. As a result, characters that are cognate among modern Chinese varieties—which have each descended from Old Chinese—are generally written with the same character.[45] Different readings of the same character are often related in both sound and meaning.
Classical Chinese is an ancient form of the written language which became the standard as Old Chinese was dying out. Its use was loosely analogous to that of Latin in pre-modern Europe; it remained the prestige written language of China until the 20th century, well after the spoken varieties descended from Old Chinese had diverged. Despite being a literary form, it retained many properties of spoken Old Chinese. Over time, with numerous sound mergers occurring throughout different varieties, the introduction of polysyllabic words increasingly served the function of reducing ambiguity between words that had since become homophonic.[46] Today, it has been estimated that over two-thirds of the 3,000 most common words in modern Standard Chinese are polysyllables, with the vast majority of these being two-syllable words.[47]
Old Chinese

Words in Old Chinese were generally monosyllabic; as such, each character denoted an independent word.[48] Affixes could be added to form a new word, which was often written with the same single character. In many cases, the pronunciations then diverged due to the systematic sound changes caused by the affixes. For example, many additional readings in modern varieties reflect the Middle Chinese 'departing tone', the major source of the 4th tone in modern Standard Chinese. Many scholars now believe that this Middle Chinese tone is the reflex of an Old Chinese derivational suffix /*-s/ called the qusheng 去聲 that served a range of semantic functions—possibly the only example of inflectional morphology extant in the otherwise analytic language.[49][50] For example:
| Character | OC[lower-greek 4] | MC[lower-greek 2] | mod. | Gloss | ||
|---|---|---|---|---|---|---|
| 傳[51] | *drjon | > | drjwen' | > | ⓘ | 'to transmit' |
| *drjons | > | drjwenH | > | ⓘ | 'a record' | |
| 磨[51] | *maj | > | ma | > | ⓘ | 'to grind' |
| *majs | > | maH | > | ⓘ | 'grindstone' | |
| 宿[52] | *sjuk | > | sjuwk | > | ⓘ | 'to stay overnight' |
| *sjuks | > | sjuwH | > | ⓘ | 'celestial mansion' | |
| 説[53] | *hljot | > | sywet | > | ⓘ | 'speak' |
| *hljots | > | sywejH | > | ⓘ | 'exhort' |
Another common sound change occurred between voiced and voiceless initials, though the phonemic voicing distinction has disappeared in most modern varieties. This is believed to reflect an Old Chinese de-transitivising prefix, but scholars disagree on whether the voiced or voiceless form reflects the original root. Note how the pairs of readings below reflect opposite transitivity from one another.
| Character | OC[lower-greek 4] | MC[lower-greek 2] | mod. | Gloss | ||
|---|---|---|---|---|---|---|
| 見[54] | *kens | > | kenH | > | ⓘ | 'to see' |
| *gens | > | henH | > | ⓘ | 'to appear' | |
| 敗[54] | *prats | > | pæjH | > | ⓘ[lower-alpha 11] | 'to defeat' |
| *brats | > | bæjH | > | 'to be defeated' | ||
| 折[55] | *tjat | > | tsyet | > | ⓘ | 'to bend' |
| *djat | > | dzyet | > | ⓘ | 'to be broken by bending' |
Vernacular Chinese
Multi-syllable words began entering the language during the Western Zhou period; it is estimated that between 25% and 30% of the vocabulary used in Warring States period texts is polysyllabic. The process has accelerated over the centuries as phonetic change has increased the number of homophones.[56] The most common process of Chinese word formation after the Classical period has been to create compounds of existing words. Words have also been created by appending affixes to words, by reduplicating words, and by borrowing words from other languages.[57] While polysyllabic words are generally written with one character per syllable, abbreviations are occasionally used.[58]
Many compound words are composed from two near-synonymous characters words, creating a new, less ambiguous form that is often used in variation with one of its component characters, depending on context. For example:
| Characters | Compound[upper-alpha 6] | |||
|---|---|---|---|---|
| 說 shuō 'to speak' |
+ | 話 huà 'speech' |
→ | 說話 shuōhuà 'to talk' |
Equally as common are nouns composed from a root and a particle suffix possessing no particular meaning, such as 子 (zǐ). These constructions serve to create a disyllabic word with the same meaning as the root character. As above, the root word usually, though not always, remains independent, in variation with the compound word.
| Characters | Compound[upper-alpha 7] | |||
|---|---|---|---|---|
| 鴨 yā '(aquatic) duck' |
+ | 子 zǐ PTC |
→ | 鴨子 yāzi[lower-alpha 12] '(aquatic) duck' |
Morphemic characters that have fallen out of use as independent words, and are now used only in compounds, are called bound forms.
| Characters | Compound[upper-alpha 8] | |||
|---|---|---|---|---|
| 桑 sāng 'mulberry tree'-BM |
+ | 树; 樹 shù 'tree' |
→ | 桑树; 桑樹 sāngshù 'mulberry tree' |
Large-scale surveys by the PRC's Ministry of Education and State Language Commission have shown strong distribution patterns in the use of characters and words. This form of analysis is essential to the quantitative research of the Chinese language, with applications in pedagogy, publishing, and information processing.[59]
The number of characters used in modern Chinese is stable, hovering around 10,000 in recent decades. Contrastingly, 80% of Chinese-language text is composed of just 590 characters, with 90% coverage achieved with 960 characters, and 99% with 2,400.[60]
History

According to Qiu Xigui, the broadest trend in the evolution of Chinese characters over their history has been simplification, both in graphical shape (字形; zìxíng), the "external appearances of individual graphs", and in graphical form (字体; 字體; zìtǐ), "overall changes in the distinguishing features of graphic[al] shape and calligraphic style, [...] in most cases refer[ring] to rather obvious and rather substantial changes".[16] Generally, within every written language using Chinese characters before the modern era, the working lexicon within texts had considerable irregularities, with many variant forms and substitutions being used.[61]
Legendary origins
Several works of classical Chinese literature indicate that, prior to the invention of characters, knotted cords were used to keep records.[62][63] The practice had some similarities to the Inca technique of quipu.[64] Works that reference the practice include chapter 80 of the Tao Te Ching[65] and the "Xici II" chapter within the Yijing.[66]
According to tradition, Chinese characters were invented by Cangjie, a mythical figure said to have been a scribe to the legendary Yellow Emperor during the 3rd millennium BCE. Frustrated by the limitations of knotting, and inspired by his study of the animals of the world, the landscape of the earth, and the stars in the sky, Cangjie is said to have invented symbols called 字 (zì)—the first Chinese characters. The legend relates that on the day the characters were created, grain rained down from the sky and that night the people heard ghosts wailing and demons crying because the human beings could no longer be cheated.[67]
Neolithic
In recent decades, a series of inscribed graphs and pictures have been found at Neolithic sites in China, including Jiahu (c. 6500 BCE), Dadiwan and Damaidi from the 6th millennium BCE, and Banpo (5th millennium BCE). Often these finds are accompanied by media reports that push back the purported beginnings of Chinese writing by thousands of years.[68][69] However, because these marks occur singly without any implied context and are made crudely, Qiu Xigui concludes that "we do not have any basis for stating that these constituted writing nor is there reason to conclude that they were ancestral to Shang dynasty Chinese characters."[70] However, they do demonstrate a history of sign use in the Yellow River valley from the Neolithic through to the Shang period.[69]
Oracle bone script

The earliest known examples of writing directly ancestral to modern characters are a body of inscriptions made on bronze vessels and oracle bones during the late Shang dynasty (c. 1250 – 1050 BCE),[71][72] with the very oldest dated to c. 1200 BCE.[73][74]: 108 Oracle bones and the script they bore were first documented by modern scholars in 1899, after examples were discovered being sold as "dragon bones" for medicinal purposes, with the symbols carved into them identified as being Chinese writing. By 1928, the source of the bones had been traced to a village near Anyang in Henan, which was excavated by the Academia Sinica between 1928 and 1937. To date, over 150,000 such fragments have been found.[71]
Oracle bone inscriptions are records of divinations performed in communication with royal ancestral spirits.[71] The inscriptions range from a few characters in length at their shortest, to around 40 characters at their longest. The Shang king would communicate with his ancestors by means of scapulimancy, inquiring about subjects such as the royal family, military success, and weather forecasting. The interpreted answers would be recorded on the divination material itself.[71]
Oracle bone script is a well-developed writing system,[75][76] suggesting that the Chinese script's origins may lie earlier than the late second millennium BCE.[77] Although these divinatory inscriptions are the earliest surviving evidence of ancient Chinese writing, it is widely believed that writing was used for many other non-official purposes, but that the materials upon which non-divinatory writing was done—likely on wood and bamboo—were less durable than bones and shells, and have since decayed away.[77]
Zhou scripts

The traditional notion of an orderly procession of scripts, with each suddenly invented and displacing the one previous, has been conclusively superseded by modern archaeological finds and scholarly research.[78] More often, it was the case that two or more scripts coexisted in a given area, and that scripts evolved gradually. As early as the Shang dynasty, oracle bone script coexisted as a simplified form alongside the normal script in bamboo books—preserved in bronze inscriptions—as well as the elaborate pictorial forms, often clan emblems, found on many bronzes.
Based on studies of these bronze inscriptions, it is clear that the mainstream script evolved in a slow, unbroken fashion from the Shang to the Zhou dynasty, until assuming the form that is now known as small seal script in the state of Qin, without any sudden shifts.[79][80] Meanwhile, other scripts had evolved during the late Zhou, especially in eastern and southern regions. These include decorative scripts such as the bird-worm seal script, and the regional 'ancient' forms of eastern Zhou states, preserved as variant forms in the Han-era Shuowen Jiezi.
Qin unification and small seal script
| Part of a series on |
| Calligraphy |
|---|
 |
Small seal script, which had evolved conservatively in the state of Qin during the Eastern Zhou, became standardised as the orthographic convention used throughout all of China by the imperial Qin dynasty. However, more than one script was in use at the time: a little-known, rectilinear, 'vulgar' form of the characters had coexisted alongside the more formal seal script for centuries in the Qin state; the popularity of this vulgar form grew as the practice of writing itself became more widespread.[81] An immature form of clerical script called "early clerical" or "proto-clerical" had already developed by the Warring States period in the state of Qin[82] based upon this vulgar form, with influence from seal script as well.[83] The coexistence of the three scripts—small seal, vulgar and proto-clerical, with the latter evolving gradually into clerical script—runs counter to the traditional belief that the Qin dynasty only used one script, and that the clerical script was suddenly invented during the early Han.
Han clerical script
The proto-clerical script matured gradually, and by the early Han period its sophistication was comparable to small seal script.[84] Recently discovered bamboo slips show the emergence of mature clerical script by the end of Emperor Wu of Han's reign in 141–87 BCE.[85]
As in previous eras, multiple scripts were in use during the Han,[86] although mature clerical script—also called 八分 (bāfēn)[87]—was dominant. An early type of cursive script was also in use at least as early as 24 BCE,[lower-alpha 13] incorporating cursive forms popular at the time, as well as elements from the vulgar writing that originated in Qin state.[88] By the time of the Jin dynasty, this Han cursive style became known as 章草 (zhāngcǎo), sometimes known in English as 'clerical cursive', 'ancient cursive', or 'draft cursive'. Some believe this name, which uses the character 章 ('orderly'), arose because the style was considered by the Jin to be a more orderly form[89] than what would become the modern form of cursive, called 今草 (jīncǎo),[90] which had first emerged during the Jin, and is still used today.
Neo-clerical
Around the midpoint of the Eastern Han,[89] a simplified and easier form of clerical script appeared, which Qiu terms 'neo-clerical' (新隶体; 新隸體; xīnlìtǐ).[91] By the end of the Han, this had become the dominant daily script in use by scribes,[89] though clerical script remained in use for formal works, such as engraved stelae.[89] Qiu describes neo-clerical as a transitional form between clerical and regular script,[89] it remained in use through the Three Kingdoms period, and into the Jin dynasty.[92]
Semi-cursive
By the late Han, an early form of semi-cursive script[91] had begun developing from a cursive form of neo-clerical script.[lower-alpha 14][93] This semi-cursive script was traditionally attributed to Liu Desheng (c. 147 – 188 CE),[92][lower-alpha 15] although such attributions refer to early masters of a script rather than to their actual inventors, since the scripts generally evolved into being over time. Qiu provides examples of early semi-cursive script, lending credence to its having popular origins, rather than being solely Liu's invention.[94]
Wei to Jin
Regular script

The design of regular script has been credited to Cao Wei calligrapher Zhong Yao (c. 151 – 230), often called the "father of regular script". However, some scholars observe that one person could not have unilaterally developed a new script which went on to see universal adoption, but could only have been a crucial contributor to the style's gradual formation. The earliest surviving manuscripts written in regular script are copies of Zhong Yao's work, including at least one copied by Wang Xizhi, often called the "Sage of Calligraphy". Regular script developed out of a neatly written form of early semi-cursive, with the addition of a 'pause' (顿; 頓; dùn) technique to end horizontal strokes, plus heavy tails on strokes which are written the downward-right diagonal.[95] Thus, early regular script emerged from a neat, formal form of semi-cursive, which had itself emerged from neo-clerical, a simplified, convenient form of clerical script. It matured further during the Eastern Jin in the hands of Wang Xizhi and his son Wang Xianzhi. However, it had not yet achieved widespread use, with most writers continuing to use the earlier neo-clerical and semi-cursive styles for daily writing,[95] with the conservative clerical script also remaining in use on some stelae.[96]
Modern cursive
Meanwhile, modern cursive script slowly emerged during this period, under the influence of both semi-cursive and the newly emerged regular script.[97] In the hands of a few master calligraphers such as Wang, modern cursive began to be formalised.[lower-alpha 16]
Maturation of regular script
It was not until the Northern and Southern period that regular script acquired a dominant status.[98] Nevertheless, it continued to evolve stylistically, only reaching full maturity during the early Tang dynasty. Some credit Ouyang Xun with producing the first examples of a mature regular script. After this point, though developments in calligraphy as an art form, as well as in the simplification of character forms would continue, there would not be another major stylistic shift for the Chinese family of scripts.
Computer encoding
Han unification is an ongoing effort by the Unicode Consortium to map each of the multiple character sets used within Chinese, Japanese, and Korean—together called the 'CJK languages'—into a single set of unified characters equally usable each language. The first release of the Unicode standard in 1991 was a major milestone of Han unification, and most text on the internet written in the relevant languages is now encoded with so-called CJK ideographs.
Structure
Broadly, Chinese characters are normally rectilinear units of uniform width. Within the square allotted to each character, most are constructed from smaller components, which are in turn drawn with a series of strokes.[99][100] Strokes can be considered both the basic unit of handwriting, as well as the basic unit of graphemic organisation within the system. Individual strokes are generally categorised according to technique and graphemic function, as exemplified by the Eight Principles of Yong. In the transition from seal to clerical script, many formerly bespoke, interlinked character components became discrete and regularised.[101][102]
Characters are assembled according to predictable visual patterns, with some components usually not seen in certain positions within a character, and some taking distinct, visually congruous forms only when in a certain position—such as the ⼑ 'KNIFE' radical appearing as 刂 on the right side of characters, but as ⺈ at the top of characters. Both the order in which strokes are drawn within a given component, as well as the order that components are assembled into whole characters is largely fixed, lending predictability and order to the writing system as a whole.[103] This is broadly summed up in practice with a few rules of thumb: generally, components and characters are assembled from left-to-right, and from top-to-bottom, with 'enclosing' components started before, then closed after, the components they enclose.[104]
For example, 字 is made up of two components, with each in turn composed of three strokes, drawn in the following order:
| Character | Component | Stroke |
|---|---|---|
 |
宀 | (1) ㇔ |
| (2) ㇔ | ||
| (3) ㇇ | ||
| 子 | (4) ㇇ | |
| (5) ㇚ | ||
| (6) ㇐ | ||
 | ||
Over a character's history, graphical variants with identical meanings called allographs emerge via several processes, possibly to facilitate ease of handwriting, or to create a more 'correct' composition to the writer, according to the principles generally used to compose and explain characters.[105] For example, individual components may be replaced with visually-, phonetically-, or semantically similar alternatives.[106] For certain characters and components, different regions may prescribe different normative stroke orders, or even different allographs of the same character.
The boundary between character structure and style, and thus between allographs of the same character versus semantically distinct characters, is often non-trivial or unclear.[107]
Methods and styles

There are numerous styles, or "scripts" (书; 書; shū) in which Chinese characters can be written, each drawing from a broader historical tradition. Most that are used throughout the Sinosphere originated within China, but may have minor regional variations. Styles created outside China tend to remain localised in their use, these include the Japanese edomoji, and the Vietnamese lệnh thư script.[108]
The oldest script style commonly used today is Qin-era seal script, though usually limited to use in the seals that lend the style its modern name. Though the art of carving traditional seals remains alive,[109] few people are still able to comfortably read them today. Clerical and regular script styles are still ubiquitous in print; when writing by hand, semi-cursive styles are also widely used. Modern use of fully cursive script is largely informal—basic character shapes are suggested rather than explicitly realised, and abbreviation is sometimes extreme. Despite being cursive to the point where individual strokes are no longer differentiable and characters are often illegible to the untrained eye, cursive writing has historically been highly revered for the beauty and freedom that it is seen to embody. Some standard simplified forms are derived from cursive, as well as the Japanese hiragana syllabary.
Calligraphy

Chinese calligraphy is usually done with ink brush, and was considered one of the four arts to be mastered by Chinese scholars. The set of rules is deliberately minimalist, but each character has a set number of brushstrokes. Strict regularity is not required, since strokes may be accentuated for dramatic effect of individual style. Calligraphy was considered a means by which scholars could artfully express their thoughts and teachings.[110]
Printing and typefaces
'Song' typefaces (宋体; 宋體; sòngtǐ)—also called 'Ming', especially in Japan, Taiwan, and Hong Kong—are named for the respective periods whose printed styles are being imitated, considered to be periods during which woodblock printing flourished in China. Ming and sans-serif are the most popular in body text.
Sans-serif typefaces, called 'black form' (黑体; 黑體; hēitǐ) in Chinese and 'Gothic' (ゴシック体) in Japanese, are characterised by simple lines of even thickness for each stroke, akin to sans-serif styles in Western typography.
Typefaces that emulate regular script are also common, but not as common as Ming or sans-serif typefaces in body text. Most typefaces in the Song dynasty were regular script typefaces, which resembled a particular calligrapher's handwriting, while most modern regular script typefaces tend toward general-purpose use.
Use with computers

Even before the advent of computers, the very first electromechanical input/output and text encoding methods to be designed were done so for use with alphabet-based writing systems, exemplified by the design of typewriters and the Morse code and ASCII standards. Adaptation of these technologies for use with a logography of thousands of characters was non-trivial.[111]
Like English and other languages, Chinese characters are output on printers and screens in different fonts.[112] In addition to the international system of measuring with points, Chinese characters are also measured by a unit called zihao (字号), first invented for Chinese printing in 1859.[113]
Input methods
Predominantly, Chinese characters are input as strings of Latin characters, which enables the use of a standard keyboard. Phonetic encodings are usually based on existing transcription schemes, such as pinyin for Mandarin, and Jyutping for Cantonese. Usually, inputting a character involves typing the transcribed syllable, possibly followed by a number representing the tone, such as 香港 ('Hong Kong') represented as xiang1gang3 in pinyin, and as hoeng1gong2 in Jyutping.
Encodings may also be based on the form of characters. Using the established rules of stroke order and how components are assembled into whole characters,[114] characters may be assigned a shorthand more unique than its phonetic transcription, potentially facilitating quicker typing. For example, using the Cangjie input method, 疆 ('border') is encoded as NGMWM, corresponding to the components 弓土一田一, with some omitted according to predictable rules. Popular form-based encoding methods include Wubi on the mainland and Cangjie in Taiwan and Hong Kong.[115]
Contextual constraints may be used to improve candidate character selection. For example, when the user types daxuejiaoshou, they may see 大学教授, a word meaning 'university professor'; when daxuepiaopiao is input, the IME may suggest 大雪飘飘, meaning 'heavy snow flying'. Though when ignoring tones 大学 and 大雪 are both transcribed as daxue, the computer can select candidates more specifically based on context.[116]
Encoding and interchange
Text is represented digitally by a series of binary code points. Since there are potentially tens of thousands of characters that may see use,[117] each requires its own encoding. In The Unicode Standard, which is the encoding now used for the majority of internet traffic worldwide, the Basic Multilingual Plane (BMP) is a sequence of 216 code points: of these, most are assigned to Chinese characters, which are termed CJK Unified Ideographs by the standard.[118] Before Unicode became predominant, the Chinese government published the GB2312 standard in 1980, which included 6,763 simplified characters. Of these, 3,755 frequently-used ones were ordered by pinyin, with the rest by radical indexing. The latest version of GB encoding is GB18030, which supports both simplified and traditional Chinese characters, and is completely one-to-one with the relevant segments of the Unicode codespace.[119] The Big5 standard was jointly developed by five Taiwanese IT companies during the early 1980s, and remains the most widely used non-Unicode encoding for Chinese characters, being comparatively popular in Taiwan, Hong Kong, and Macau.
In non-Chinese languages
Most prominently, the Korean, Japanese and Vietnamese languages have historically been written with Chinese characters, used for record-keeping, histories, and official communications.[120] In these languages, Chinese characters have often been used to represent Chinese loanwords.[121] Some characters retained their phonetic elements based on their pronunciation in a historical variety of Chinese from which they were acquired. These adaptations of Chinese pronunciation are known as Sino-Xenic pronunciations, and have been useful in the linguistic reconstruction of Middle Chinese.
Chinese characters were used in Vietnam during the millennium of Chinese rule that began in 111 BCE; they were originally used for writing Classical Chinese, but were adapted around the 13th century to write the Vietnamese language, creating the chữ Nôm script.
Chinese characters arrived in Korea beginning in the 2nd century BCE, alongside influences such as Buddhism; over the following three centuries, their use became widespread.[122] From Korea, the characters spread to Japan language during the 5th century CE.
Currently, the only non-Chinese language normally written with Chinese characters is Japanese. Vietnam abandoned the use of chữ Nôm and Classical Chinese in the early 20th century in favour of a Latin alphabet, and Korea has largely replaced the use of hanja with hangul. Since education regarding Chinese characters is not mandatory in South Korea,[123] the usage of hanja is rapidly disappearing.
Japanese
 |
| Japanese writing |
|---|
| Components |
| Uses |
| Transliteration |
In the Japanese writing system, Chinese characters used are known as kanji. Japanese historically borrowed many words from Chinese, which were written with their original characters, while native Japanese words were also written with orthographic borrowings of Chinese characters with similar meanings. Most kanji arrived via both borrowing processes, and thus have both native Japanese readings, known as kun'yomi, as well as Chinese-original readings, known as on'yomi. Moreover, Chinese words were often borrowed multiple times from different varieties and at different times, resulting in several distinct on'yomi readings for the same character.[124] Modern Japanese uses kanji for most word stems, as well as hiragana and katakana, a pair of syllabaries collectively known as kana. Hiragana are used to write words, including grammatical inflections and particles, and katakana are used for transcribing non-Chinese loanwords, as well as for emphasis of native words, similar to how italics are used in languages written with the Latin script.[125] The syllabaries were derived by simplifying Chinese characters selected to represent Japanese syllables; they differ from one another in part because each selected different characters for certain syllables, in addition to the different strategies employed to reduce the characters for easy writing. The angular katakana were obtained by selecting a smaller component from each character, while the curving hiragana were based on the cursive form of the entire character.[126]
Due to Japanese being a synthetic language, many words consist of multiple syllables, and as such many kanji have multi-syllable pronunciations. For example, the kanji 刀 has a native kun'yomi reading of katana. In different contexts, it can also be read with the on'yomi reading tō, such as in the Chinese loanword 日本刀, nihontō, 'Japanese sword', whose pronunciation descends from the Chinese pronunciation at the time of borrowing. (In contemporary Standard Chinese, the word is pronounced rìběndào.) While modern loanwords from languages outside of the Sinosphere are usually written with katakana, loanwords prior to the Meiji era were typically written with unrelated kanji whose on'yomi had the same pronunciation as the syllables in the loanword. These spellings are called called ateji: for example, 亜米利加 was written for modern アメリカ, Amerika, 'America', 歌留多 or 加留多 for modern カルタ, karuta, 'card', 'letter', and 天婦羅 or 天麩羅 for modern テンプラ, tenpura, 'tempura'. Only some ateji spellings are still in common use, such as 缶, kan, 'can'.
Korean
As early as the Gojoseon period, Classical Chinese was the dominant form of written communication in Korea. Although the hangul alphabet was invented by the Joseon king Sejong in 1443, it was not taken up by Korean literati, and did not come into widespread use until the late 19th century.[127][128] Even today, much of the Korean vocabulary, especially in areas of science and sociology, comes directly from Chinese. However, due to the lack of tones in the Korean language, many dissimilar Sino-Korean words took on identical pronunciations, and as such are spelled identically in hangul.[129] For example, the phonetic dictionary entry for 기사, gisa yields more than 30 different entries. In the past, this ambiguity had been efficiently resolved by parenthetically displaying the associated hanja. While hanja is sometimes used for Sino-Korean vocabulary, native Korean words are rarely, if ever, written in hanja.
When learning to write hanja, students are taught to memorise both native and Sino-Korean Korean pronunciations for each hanja. The collation of hanja is similar to if the word water were listed as 'water; aqua', 'horse; equus', or 'gold; aurum', as hybridisations of the English and Latin terms.[130] Examples of listings include:
| Hanja | Hangul | Gloss | |
|---|---|---|---|
| Native | Sino-Korean | ||
| 水 | 물, mul | 수, su | 'water' |
| 人 | 사람, saram | 인, in | 'person' |
| 大 | 큰, keun | 대, dae | 'big' |
| 小 | 작을, jakeul | 소, so | 'small' |
| 下 | 아래, arae | 하, ha | 'down' |
| 父 | 아비, abi | 부, bu | 'father' |
| 韓 | 나라 이름, nara ireum | 한, han | 'Korea' |
South Korea
Hanja are still used in South Korea, particularly in newspapers, weddings, place names, and the practice of calligraphy—although to nowhere near the extent of kanji use in Japanese society. At present, Chinese characters are sometimes used for the disambiguation of homophonous words. Additionally, their use still possesses connotations of erudition and cultural Confucianism; knowledge of Chinese characters is considered to be a high class attribute by many Koreans, and an indispensable part of a classical education.[128] There is a clear trend toward the exclusive use of hangul in ordinary South Korean contexts.[131] Its use has become a politically contentious issue in the country, with some urging a "purification" of the national language and culture by totally abandoning their use and ending hanja education in schools, and instead exclusively using hangul throughout society and the in public schools. Others support a revival of ordinary hanja use, such as was the case in the 1970s and 80s.[132]
Policies regarding the teaching of hanja have historically vacillated, often swayed by the inclinations of individual education ministers. Students in grades 7–12 are presently taught 1,800 characters,[132] albeit with a principal focus on simple recognition, with the aim of achieving newspaper literacy.[128] Hanja retains its prominence in Korean academia, as the vast majority of Korean documents, history, and literature (such as the Veritable Records of the Joseon Dynasty) were written in Classical Chinese using hanja. Therefore, a working knowledge of Chinese characters is still important for anyone wishing to interpret and study older Korean texts, or anyone who wishes to read scholarship in the humanities. Working knowledge of hanja is also useful for understanding the etymology of Sino-Korean vocabulary.[133]
North Korea
A 1949 law in North Korea apparently banned the use of all so-called foreign languages, which has been interpreted as including hanja, even the then-newly proposed New Korean Orthography. However, due to the country's isolation accurate reports about its use of hanja are difficult to obtain. A textbook for university history departments published in the country in 1971 contained 3,323 distinct characters, and in the 1990s North Korean school children were still expected to learn 2,000 characters, more than in South Korea or Japan.[134] A 2013 textbook appears to integrate the use of hanja in secondary school education.[135] Currently, North Korea is estimated to teach around 3,000 hanja to North Korean students by the time they graduate university; in some cases, the characters appear within advertisements and newspapers, but cultural use is narrower than in the South, mostly restricted to dictionaries and textbooks.[136]
Okinawan
Chinese characters are thought to have been first introduced to the Ryukyu Islands in 1265 by a Japanese Buddhist monk.[137] After the Okinawan kingdoms became tributaries of Ming China, especially the Ryukyu Kingdom, Classical Chinese was used in court documents, but hiragana was mostly used for popular writing and poetry. After Ryukyu became a vassal of Japan's Satsuma Domain, Chinese characters became more popular, as well as the use of kanbun. In modern Okinawan, which is labelled as a dialect of Japanese by the Japanese government, katakana and hiragana are mostly used to write Okinawan, but Chinese characters are still used.
Vietnamese

Until the early 20th century, Literary Chinese (Hán văn) was used in Vietnam for all official and scholarly writing. The chữ Nôm script began to be developed around the 13th century to record folk literature in the Vietnamese language. Chinese characters, called chữ Hán (𡨸漢), chữ Nho (𡨸儒), or Hán tự (漢字), are now limited to ceremonial use in Vietnam.
The oldest written Chinese text found in Vietnam is an epigraphy dated to the year 618, erected by local Sui officials in Thanh Hóa.[138] Similar to Zhuang sawndip, some chữ Nôm characters were created by combining semantic character components with phonetic components that resembled Vietnamese syllables.[139] This process resulted in a highly complex system whose use was limited to a small portion of the Vietnamese population, never more than 5%.[140] The oldest chữ Nôm written alongside Chinese is a Buddhist inscription dated to 1209.[139] Before 1945, the library of the French School of the Far East (EFEO) in Hanoi collected a total of around 20,000 Chinese and Vietnamese epigraphy rubbings from throughout Indochina.[141] The oldest surviving extant manuscript in Vietnamese is a late 15th-century bilingual copy of the Buddhist Sutra of Filial Piety, currently kept by the EFEO. It features Chinese text in larger characters, and an Old Vietnamese translation in smaller characters glossing the text.[142] Every Hán Nôm book in Vietnam after the Phật thuyết is dated between the 17th and the 20th centuries, with most being hand-copied works, and few printed texts. By 1987, the library of the Institute of Hán-Nôm Studies in Hanoi had collected a total of 4,808 Hán Nôm manuscripts.[143]

Classical Chinese and chữ Nôm fell out of use during the French colonial period, and were gradually replaced with the Vietnamese alphabet, which uses Latin characters and remains the primary writing system for Vietnamese.[144][145] Contemporaneous use of chữ Hán in Vietnam is often connected with traditional culture, such as the practice of calligraphy.
Other languages
Several minority languages of South and Southwest China were formerly written with scripts based on Chinese characters, but also included many locally created characters. The most extensive is the sawndip script used to write the Zhuang languages of Guangxi, which is still in use despite efforts to encourage the writing of Zhuang with a Latin-based alphabet. Other languages written with such scripts include Miao, Yao, Bouyei, Mulam, Kam, Bai, and Hani.[146] All these languages are now officially written using Latin-based scripts. According to surveys, traditional sawndip script has twice as many users as the official Latin script.[147]
The foreign dynasties that ruled northern China between the 10th and 13th centuries developed scripts that were inspired by Chinese characters but did not use them directly: the Khitan large script, Khitan small script, Tangut script, and Jurchen script—though Chinese characters were used to phonetically transcribe the language of the Jurchen people, renamed the 'Manchu' after the founding of the Qing dynasty. Other scripts within China that have adapted a few Chinese characters but are otherwise distinct include the Geba script, Sui script, Yi script, and the Lisu syllabary.[146]
Transcription

Along with the Persian and Arabic scripts, the Mongolian language was also written with Chinese characters phonetically transcribing Mongolian sounds. Notably, the only surviving copies of The Secret History of the Mongols were written in such a manner.
According to the 19th century missionary John Gulick:
"The inhabitants of other Asiatic nations, who have had occasion to represent the words of their several languages by Chinese characters, have as a rule used unaspirated characters for the sounds g, d, b. The Muslims from Arabia and Persia have followed this method ... The Mongols, Manchu, and Japanese also constantly select unaspirated characters to represent the sounds g, d, b, and j of their languages. These surrounding Asiatic nations, in writing Chinese words in their own alphabets, have uniformly used g, d, b, etc., to represent the unaspirated sounds."[148]
Standard forms
In each region, the latest published standards for character forms are:
| Polity | Standard | Characters | Latest revision |
|---|---|---|---|
| Table of General Standard Chinese Characters | 8105 | 2013[149] | |
| List of Graphemes of Commonly-Used Chinese Characters | 4762 | 2012[150] | |
[lower-alpha 17] | Chart of Standard Forms of Common National Characters | 4808 | 1983[152] |
| Chart of Standard Forms of Less-Than-Common National Characters | 6341 | 1983[153] | |
| Chart of Rarely-Used National Characters | 18388 | 2017[151] | |
| Jōyō kanji | 2136 | 2010[154] | |
| Basic Hanja for Educational Use | 1800 | 2000[155] |
In addition to specificity in character size and shape, Chinese characters are written with very precise rules regarding the strokes employed, as well as their placement and ordering. Just as each region has standardised forms, each also has standard stroke orders. Most characters have only one standard stroke order, though some words may differ in stroke order by region, even occasionally resulting in different stroke counts.
There is often considerable overlap between the concepts of 'style' and 'form'; with the advent of Unicode, this distinction has challenged the process of Han unification. The designers of the Noto CJK family of typefaces, a collaboration between Google and Adobe, researched the regional distinctions in Chinese character forms extensively, as to create a general-purpose, neutral typeface family—and not release fonts meant to write Japanese that looked "too Chinese", or vice-versa.[156]
Received forms

With the use of woodblock printing, there was a considerable consolidation in forms prior to the standardisation efforts of the 20th century, especially during the Ming. These orthodox forms are in turn well-represented in touchstone reference works throughout the modern era, such as the 1716 Kangxi Dictionary and the 1915 Zhonghua Da Zidian.
Simplified characters
One of the earliest proponents of character simplification was Lufei Kui, who proposed in 1909 that simplified characters should be used in education. In the years following the Xinhai Revolution and its associated May Fourth Movement, many anti-imperialist Chinese intellectuals sought ways to modernise China as quickly as possible. Traditional culture and values were challenged and subsequently blamed for societal and economic problems. Soon, people in the movement began pointing to the traditional Chinese writing system as an obstacle to the modernisation of China, proposing that it should either be reformed or abolished entirely. Lu Xun, a renowned 20th century author, stated 'If Chinese characters are not destroyed, then China will die'.[157]

During the 1930s and 1940s, discussions on character simplification took place within the Kuomintang government, and a large number of the intelligentsia maintained that character simplification would help boost literacy throughout the country.[159][160] In 1935, a table of 324 simplified characters collected by Qian Xuantong was introduced as the first official batch of simplified characters; however, it was rescinded in 1936 due to fierce opposition within the party.


Although most closely associated with the PRC, the modern process of character simplification began well before 1949. Cursive script were the source of inspiration for many of the simplified forms, while others were already used in print, albeit not for most formal works. With the goal of increasing functional literacy, a major concern at the time, discussions on character simplification took place among Chinese intelligentsia and within the Kuomintang (KMT) government during the Republican period.[161] This earlier initiative to simplify the Chinese writing system was later inherited and implemented by the Communists after its subsequent abandonment by the KMT.
The use of traditional versus simplified characters varies greatly, and can depend on both the local customs and the medium. Before official reforms, character simplifications were not officially sanctioned and generally took the form of vulgar variants and idiosyncratic substitutions. Unofficial, often simplified forms would be used in everyday writing or for quick notes. Since the 1950s, the PRC has officially encouraged the use of simplified characters on the mainland. Along with the Republic of China, Hong Kong and Macau—at the time still under colonial rule—were not affected by the reform. There is no firm rule for which characters to use, and often it is determined by tastes and inclinations of the audience and writer.
In other Sinophone countries, the use of simplified characters is generally more common among younger people, while many older generations literate in Chinese still use traditional forms. Outside of China, Chinese-language shop signs are also often written using traditional characters.
People's Republic of China
Most simplified forms in use today are the direct result of PRC initiatives during the 1950s and 1960s. During the transitional years, while considerable confusion about the character forms was still rampant, transitional characters mixing simplified and yet-to-be simplified components appeared sporadically, then disappeared. Before largely settling on simplifying the existing system, some within the PRC, including Mao Zedong, also explored the total replacement of Chinese characters with a phonetic script, usually based on the Latin alphabet, culminating in projects such as Gwoyeu Romatzyh and Latinxua Sin Wenz.[162]
The PRC initiated the first round of simplifications with two documents published in 1956 and 1965. The reforms both simplified the forms of many characters in use, and reduced the total number of characters in the lexicon.[163] The majority of first round characters were drawn from conventional abbreviated or ancient forms.[164] For example, the orthodox character 來 was written as 来 in the earlier clerical script; it used one fewer stroke, and was thus adopted as a simplified form. The 雲 ('cloud') character was written as 云 in the ancient oracle bone script. This simpler form had remained in use later as a phonetic loan with a meaning of 'to say', and with the original meaning of 'cloud' it was instead written with an added ⾬ 'RAIN' radical as a semantic indicator. When using simplified forms, these two characters are merged into 云.[upper-alpha 9]
A second round of simplifications was promulgated in 1977, but it was poorly received by the public, and fell out of official use very quickly, ultimately being formally rescinded in 1986. The second round of simplifications were unpopular in large part because the vast majority of its forms were completely new, in stark contrast to the many familiar variants present in the first round.[165]
Two revised lists of simplified characters were published in 1988: the List of Commonly Used Characters in Modern Chinese having 2,500 common characters and 1,000 less common characters, and the Chart of Generally Utilised Characters of Modern Chinese with 7,000 characters, including those in the smaller list. In 2013, the revised Table of General Standard Chinese Characters replaced the 1988 lists as the new standard: it includes 8,105 characters, with 3,500 categorised as primary, 3,000 as secondary, and 1,605 as tertiary.[166] GB 2312, an early version of the national encoding standard used in the PRC, has 6,763 code points; its modern, mandatory successor GB 18030 has a much higher number.[167] The Chinese Proficiency Test (HSK) covers 2,663 characters and 5,000 words at its highest level, while the Chinese Proficiency Grading Standards for International Chinese Language Education would cover 3,000 characters and 11,092 words at the highest level.[168][169][170]
Singapore
Singapore underwent three successive rounds of character simplification promulgated by the Ministry of Education, with the first two having some simplifications that differed from those used in mainland China. The first round was published in 1969, and consisted of 498 simplified and 502 traditional characters. The second round in 1974 consisted of 2287 simplified characters, including 49 differences from the PRC system that were removed with the final round in 1976.[171] In 1993, Singapore adopted the 1986 revisions made in mainland China.
Unlike in mainland China, where personal names may only be registered using simplified characters, Singapore parents have the option of registering their children's names in traditional characters.[172]
Malaysia
Malaysia uses simplified characters in Chinese-language schools. Chinese-language newspapers in the country are published in either simplified or traditional characters—often, headlines are printed with traditional forms, and the body with simplified forms.
Philippines
In the Philippines, most Chinese schools and businesses still use the traditional characters with bopomofo, owing from influence from Taiwan due to shared Hokkien heritage. Recently, however, more Chinese schools now use both simplified characters and pinyin. Since most readers of Chinese newspapers in the Philippines belong to the older generation, they are still published largely using traditional characters.
Traditional characters

Taiwan
In Taiwan, the Ministry of Education's Chart of Standard Forms of Common National Characters lists 4,808 characters; the Chart of Standard Forms of Less-Than-Common National Characters lists another 6,341 characters. The Chinese Standard Interchange Code (CNS11643)—the official national encoding standard—supported 48,027 characters in its 1992 version; currently encoding over 96,000 characters,[173] while BIG-5, the most widely used non-Unicode encoding, supports only 13,053. The Test of Chinese as a Foreign Language (TOCFL) covers 8,000 words at its highest level. The Taiwan Benchmarks for the Chinese Language (TBCL), a guideline designed to describe levels of Chinese language proficiency, covers 3,100 characters and 14,425 words at the highest level.[174][175]
Hong Kong
In Hong Kong, which uses traditional characters, the Education and Manpower Bureau's List of Graphemes of Commonly-Used Chinese Characters, containing 4,759 characters, is intended for use in elementary and junior secondary education.
North America
Chinese-language signage in the United States and Canada most often uses traditional characters.[176] There is some effort to get municipal governments to implement more simplified character signage due to recent immigration from mainland China.[177] Most Chinese-language newspapers in North America are printed using traditional characters.
Kanji
After World War II, the Japanese government also instituted a series of orthographic reforms. Some characters were given simplified forms called shinjitai; the older forms were then labelled the kyūjitai. The use of numerous variant forms was discouraged, and lists of characters to be learned during each grade of school were created: first the 1850-character tōyō kanji list in 1945, and then the 1945-character jōyō kanji list in 1981, with a 2136-character revision in 2010. The Japanese government restricts characters that can be used in names to the jōyō kanji plus an additional list of 983 jinmeiyō kanji historically prevalent in names.[178][179] While these lists serve as a guideline, unlisted characters are still widely used by native Japanese speakers, such as the kyūjitai form of 'dragon' (龍) alongside the shinjitai form (竜).
Variant forms
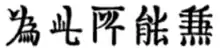
Just as letters in the Latin script have characteristic shapes—for example, with lowercase letters mostly occupying the x-height, and certain letters having distinctive ascenders or descenders—Chinese characters characteristically occupy a roughly square area within which components are to fit, in order to maintain a uniform size and shape—especially with small printed characters in Ming and sans-serif styles. Beginners often practise writing on graph paper with grid lines; Chinese people sometimes use the term 'square-block characters' (方块字; 方塊字; fāngkuàizì), also translated as 'tetragraphs',[180] in reference to written characters.
Despite standardisation, use of certain non-standard forms has been common historically, especially in handwriting. In older sources, even authoritative ones, variant characters are easily found.[181] While orthodox forms were mandatory in official and semi-official printed works, many printers produced works of varying quality, with errata including the deletion of passages, the apparent forgery of earlier styles, as well as the non-normative use of characters, portrayed either as incorrect variant forms or as outright typos.[182] In the preface to the Kangxi Dictionary, there are 30 variant characters which are not found in the dictionary itself.[183]
Contractions and abbreviations
In certain cases, compound words and set phrases may be represented by single-character contractions. Some of these can be considered logograms, where characters represent whole words rather than syllable-morphemes, though these are generally considered as non-standard ligatures or abbreviations instead—similar to scribal abbreviations such as an ampersand for the digraph et, or an ñ for the digraph nn. These usually see use in handwriting or decorations, but sometimes in print as well. These ligatures are called 合文; héwén, 合书; 合書; héshū or 合体字; 合體字; hétǐzì in Chinese; in the special case where two characters are combined, they are known as 'two-syllable characters' (双音节汉字; 雙音節漢字; shuāngyīnjié hànzì).
A commonly seen example is the 'double happiness' character 囍, formed as a ligature of 喜喜 and referred to by its disyllabic name 双喜; 雙喜; shuāngxǐ.[upper-alpha 10] In handwriting, numbers are very frequently squeezed into one space or combined—common ligatures include 廿; niàn; 'twenty', normally read as 二十; èrshí, 卅; sà; 'thirty', normally read as 三十; sānshí, and 卌; xì; 'forty', normally read as 四十; sìshí in Standard Mandarin,[upper-alpha 11][8] though other Chinese varieties may differ. For example, 廿 is given a monosyllabic reading of jaa6 in Cantonese.[184] Calendars often use numeral ligatures in order to save space, and in modern printings of the traditional Chinese calendar, the use of 廿 is standard. Thus, one would generally write "21 March" as 三月廿一.
Examples of modern contractions include characters sometimes used to represent SI units. In Chinese these units are disyllabic and usually written with two characters, as with 'centimetre' (厘米; límǐ) from 厘; 'centi-' and 米; 'metre', or 'kilowatt' (千瓦; qiānwǎ). However, in the 19th century these were often written via compound characters, pronounced disyllabically, such as 瓩 for 千瓦 or 糎 for 厘米—some of these characters were also used in Japan, where they were pronounced with borrowed European readings instead. These have now fallen out of general use, but are occasionally seen. Less systematic examples include 图; 圕 (tuān), a contraction of 图书馆; 圖書館 (túshūguǎn; 'library').[upper-alpha 12] Since polysyllabic characters are often non-standard, they are often excluded from character dictionaries.
The use of such contractions is as old as the characters themselves, and they have frequently been used in religious or ritual contexts. In the oracle bone script, personal names, ritual items, and even phrases are commonly contracted into single characters, such as 受又 (shòu yòu; 'receive blessings') becoming 祐 (yòu). A dramatic example is found in medieval manuscripts, where 'bodhisattva' (菩萨; 菩薩; púsà) is sometimes contracted to a single character composed of four 十 arranged in a 2×2 grid—derived from the 艹 'GRASS' radicals present in the original characters.[8] For the sake of consistency and standardisation, the Chinese government has sought to limit the contemporary use of polysyllabic characters in public writing.[8]
Conversely, with the erhua phenomenon in Mandarin varieties, expressed via the fusion of the diminutive 儿; ér suffix, some monosyllabic words may be written with two characters, such as in huār (花儿; 'flower').
Multi-syllable morphemes
Chinese characters are primarily morphosyllabic, meaning that there is usually a one-to-one correspondence between Chinese morphemes and spoken Chinese syllables, and therefore written Chinese characters. However, in modern Chinese varieties most common words are disyllabic and therefore dimorphemic. In modern Standard Chinese, 10% of morphemes are bound forms, only appearing in compound words. However, a few morphemes are disyllabic, some of which even date back to Classical Chinese.[185] Excluding loanwords, these are typically words for plants and small animals, usually written with a pair of phono-semantic compounds sharing a common radical. Examples are 蝴蝶 (húdié; 'butterfly') and 珊瑚 (shānhú; 'coral')—the first character of 'butterfly' and the second character of 'coral' each have 胡 for a phonetic component, with the ⾍ 'INSECT' and ⽟ 'JADE' radicals as their respective semantic components, also present within the other character of each word. Neither of the aforementioned hú characters exist as independent morphemes, except as poetic abbreviations of the disyllabic words.
Rare and complex characters
Often a rare character, complex, or antiquate variant will appear in personal or place names. As many computer encoding systems have historically included only the most common characters, this can create problems. As a representative example, the name of Taiwanese politician Yu Shyi-kun contains the rare character 堃 (kūn); printing this character is often nontrivial. Newspapers covering Yu that encountered difficulty with his name dealt with this problem in various ways, including using software to combine two extant characters into a visually similar amalgam, embedding a picture of the character instead of encoding it as text, substituting a homophonic character with the expectation that the reader would make the correct inference. Generally, printed materials in Taiwan will annotate such a character with bopomofo. Japanese newspapers often replace obscure characters with katakana instead, as is accepted practice in Japanese style guides.
There are also extremely stroke-rich characters, which tend to be rare. A notable example is 𪚥 (zhé; 'verbose'), which fell out of use by the end of the 5th century, containing 64 strokes. This character may not necessarily be seen as the most complex or difficult, as it simply requires writing the 16-stroke character 龍 (lóng; 'dragon') four times within the space allotted for one. Another 64-stroke character created in the same manner is 𠔻 (zhèng), composed of the character 興 (xīng, xìng; 'flourish') in quadruplicate.
One of the most complex characters found in modern Chinese dictionaries is 齉 (nàng; 'snuffle') with 36 strokes.[upper-alpha 13] Other stroke-rich characters include the triplicated 靐 (bìng) with 39 strokes, and the quadruplicated 䨻 (bèng) with 52, both meaning 'the loud noise of thunder'—however, these are not commonly used. As an example, the most complex character that can be input with a representative IME[lower-alpha 19] is 龘 (dá; 'appearance of a dragon in flight'). It is composed of the ⿓ 'DRAGON' radical in triplicate, having a total of 16 × 3 = 48 strokes. Among the most complex characters presently in common use are 籲 (yù; 'to implore') with 32 strokes, 鬱 (yù; 'luxuriant', 'lush', 'gloomy')—also the character in the jōyō kanji list having the most strokes, with 29—豔 (yàn; 'colourful') with 28, and 釁 (xìn; 'quarrel') with 25. Also occasionally in modern use is 鱻 (xiān; 'fresh'), a variant of 鮮 with 33 strokes.
In Japanese, an 84-stroke kokuji exists: ![]() , normally read taito. It is composed of the 'cloud' character 䨺 atop the aforementioned triple-'dragon' character, also possessing the meaning of 'appearance of a dragon in flight': it has readings おとど, otodo, たいと, taito, and だいと, daito.[186]
, normally read taito. It is composed of the 'cloud' character 䨺 atop the aforementioned triple-'dragon' character, also possessing the meaning of 'appearance of a dragon in flight': it has readings おとど, otodo, たいと, taito, and だいと, daito.[186]
 Zhé, 'verbose'
Zhé, 'verbose' Zhèng, meaning unknown
Zhèng, meaning unknown Nàng, 'snuffle'
Nàng, 'snuffle' Taito, 'appearance of a dragon in flight'
Taito, 'appearance of a dragon in flight' Alternative form of taito
Alternative form of taito.svg.png.webp)
Lect-specific variants
In addition, there are a number of 'dialect characters' (方言字; fāngyánzì) that are not generally used in formal written Chinese but represent colloquial terms in various spoken varieties of the language. In general, it is common practice to use standard characters to transcribe previously-unwritten words in Chinese dialects when obvious cognates exist. However, when no obvious cognate exists due to factors like irregular sound changes or semantic drift over time, or an origin in a non-Chinese language, like a substratum or loanword, then characters to transcribe it are borrowed according to the rebus principle, or invented in an ad hoc manner. These new characters are generally phono-semantic compounds, e.g. Min Nan 侬 ('person'), although there are examples of compound ideographs, e.g. northeast Mandarin 孬 ('bad').
There may be several ways to write a dialectal word—often, one that is etymologically correct, and one or several that are based on the word's pronunciation—e.g. the etymological 觸祭 versus the phonetic 戳鸡 (7tshoq1ci) in Shanghainese, meaning 'eat'. Speakers of a dialect will generally recognise a dialectal word if it is transcribed according to pronunciation, while the etymologically correct form may be more difficult to recognise. For example, few Gan speakers would recognise the character 隑 as meaning 'to lean' in their dialect,[upper-alpha 14] because this sense of the character is now archaic in Standard Mandarin.
As an exception, written Cantonese is widespread in Hong Kong, even for certain formal documents, due to the former British colonial administration's recognition of Cantonese for use for official purposes. In Taiwan, there is also a body of semi-official characters used to represent Taiwanese Hokkien and Hakka. An example of an Hakka vernacular character is 㓾 (cii11, 'kill').[upper-alpha 15] Other varieties of Chinese with a significant number of speakers—like Shanghainese Wu, Gan Chinese, and Sichuanese Mandarin—also have their own series of characters, but these are not often seen, except on advertising billboards directed toward locals and are not used in formal settings except to give precise transcriptions of witness statements in legal proceedings. Standard Chinese is the preferred written language within every region of mainland China.
Indexing
Dozens of schemes have been devised for indexing Chinese characters and sorting them into dictionaries. Most of these are specific to the dictionary for which they were invented, and relatively few have seen widespread use. Often, character dictionaries incorporate several means for which users may locate entries. Traditionally, methods for organising and sorting Chinese dictionaries have been divided into form-based orders, which sort by graphical properties such as constituent components, sound-based orders, usually based on an extant transliteration scheme such as pinyin or bopomofo, and meaning-based orders.[187]
Many Chinese-, Japanese-, and Korean-language character dictionaries are indexed using a technique known as radical-and-stroke sorting, in which characters are grouped by common components called radicals, with radicals in turn ordered by number of strokes. The characters under each radical heading are in turn listed in order of their total number of strokes. Grouping by radical was introduced in the Shuowen Jiezi, which used 540 radicals. The 214 Kangxi radicals were introduced in the Zihui in 1615, and later popularised by the 1716 Kangxi Dictionary.
For example, to locate the character 松 ('pine tree') in such a dictionary, the user first determines which part of the character is the radical—here, the radical is ⽊ 'TREE'. One then counts the number of strokes in the radical (four). Within the radical index, usually located on one of the dictionary's inside covers, the page number of the section heading for ⽊ 'TREE' is listed, alongside those of the other radicals with four strokes. The user can then turn to the appropriate section heading, which will have a sub-index with page numbers that correspond to the number of strokes present in the remainder of the character. The right half of 松 also contains four strokes—upon turning to the corresponding page number, the user can now scan the entries to locate the character in question. Some dictionaries have a sub-index listing every character containing a given radical: if the user knows the number of strokes in the non-radical portion of the character, they can use this to obtain the page number directly.
Another form-based system is the four-corner method, in which characters are classified according to the shapes at each of the rectilinear character's corners. In modern Chinese, characters and words are also ordered by their frequency, as determined by use within a corpus, often with the aid of a computerised database. Important stroke-based sorting methods include stroke-count sorting, stroke-count-stroke-order sorting, GB stroke-based sorting and YES sorting.
Most modern Chinese dictionaries arrange the main character entries alphabetically according to pinyin spelling, but also provide a traditional radical-based index in the front of the dictionary.[188] To find a character with an unknown pronunciation using one of these dictionaries, the reader determines the radical and stroke number of the character, as before, and locates the character in the radical index. The character's entry will give the character's pronunciation in pinyin or the page number of the main character entry.
Number of characters
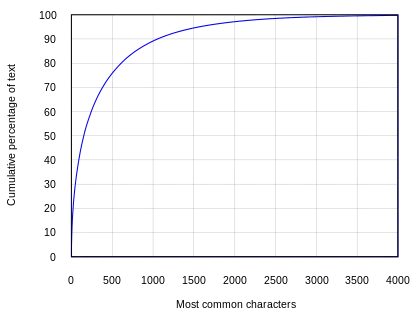
Studies within China have suggested that literate individuals have an active vocabulary of between 3,000 and 4,000 characters, while specialists in fields like classical literature or history are estimated to have a working vocabulary of between 5,000 and 6,000 characters.[190]
Kanji

The Japanese Ministry of Education has designated 2,136 jōyō kanji to be taught in primary and secondary school. Today, a well-educated Japanese person may know upwards of 3,500 characters.[191] The kanji kentei tests a speaker's ability to read and write kanji. The highest level of the kanji kentei tests according to the full JIS X 0208 list, which includes over 6,000 kanji.[192]
Hanja
The South Korean Basic Hanja for Educational Use is a set of 1,800 characters standardised in 1972, with the first 900 hanja taught to middle school students, and the rest taught to high school students.[155]
In March 1991, the Supreme Court of Korea published the 2,854-character Table of Hanja for Use in Personal Names.[193] The list expanded gradually: by 2015 there were 8,142 hanja, including the set of basic hanja, permitted for use in Korean names.[194]
Large character lists
Ostensibly, Chinese characters can be created and used arbitrarily, though they are unlikely to gain widespread use or inclusion in official character sets.[195] Counting the entries within major Chinese dictionaries is a viable means of estimating the growth of the character inventory over time.
Estimates of the total number of characters in modern use can be sourced from encoding schemes and dictionaries:[196] according to sources from mainland China, Taiwan, Hong Kong, Japan, and Korea, this number is likely around 15,000.[197] For comparison, Unicode encodes over 90,000 CJK Unified Ideographs.[198]
| Year | Dict. | Char. |
|---|---|---|
| 100 | Shuowen Jiezi | 9,353[199] |
| 230 | Shenglei | 11,520[199] |
| 350 | Zilin | 12,824[199] |
| 543 | Yupian | 16,917[200][201] |
| 601 | Qieyun | 12,158[202] |
| 732 | Tangyun | 15,000[199] |
| 753 | Yunhai jingyuan | 26,911[203] |
| 997 | Longkan Shoujian | 26,430[204] |
| 1011 | Guangyun | 26,194[201][205] |
| 1066 | Leipian | 31,319[203] |
| 1039 | Jiyun | 53,525[206] |
| 1615 | Zihui | 33,179[201][207] |
| 1675 | Zhengzitong | 33,440[208] |
| 1716 | Kangxi Dictionary | 47,035[201][209] |
| 1915 | Zhonghua Da Zidian | 48,000[201] |
| 1989 | Hanyu Da Zidian | 54,678[199] |
| 1994 | Zhonghua Zihai | 85,568[210] |
| 2017 | Dictionary of Chinese Character Variants | 106,330[211] |
| Year | Dictionary | Language | Number of characters |
|---|---|---|---|
| 2003 | Dai Kan-Wa Jiten | Japanese | 50,305[212] |
| 2008 | Han-Han Dae Sajeon | Korean | 53,667[213] |
Even the Zhonghua Zihai does not include characters in the Chinese family of scripts created to represent non-Chinese languages, except the unique characters in use in Japan and Korea. Characters formed by Chinese principles in other languages include the roughly 1,500 Japanese-made kokuji given in the Kokuji no Jiten,[214] the Korean gukja, the over 10,000 sawndip characters still in use in Guangxi, and the almost 20,000 Nôm characters historically used in Vietnam.[215] More divergent descendants include the Tangut script, which created over 5,000 characters with visually similar strokes to Chinese characters, but different principles of formation.
Modified radicals and new variants are two common reasons for the ever-increasing number of characters. There are about 300 radicals, with 100 being in common use. Creating a new character by modifying the radical is an easy way to disambiguate homographs among picto-phonetic compounds (xíngshēngzì). This practice began long before the Qin standardisation of Chinese script. The third-person personal pronoun 他 (tā) written with the ⼈ 'MAN' radical, traditionally used regardless of the target's gender or animacy, illustrates modifying signifiers in order to form new characters. In modern written Chinese, further graphical distinctions have been made between 她 ('she') with the ⼥ 'WOMAN' radical, 牠 ('it') with the 牜 'COW' radical, 它 ('it') with the ⼧ 'ROOF' radical, and 祂 ('He') with the 礻 'SPIRIT' radical, though all are pronounced identically as tā. One consequence of modifying radicals is the fossilisation of rare and obscure variant logographs, some of which are not even found in Classical Chinese texts. For instance, 和 (hé; 'harmony', 'peace'), which combines the ⽲ 'GRAIN' radical with the ⼝ 'MOUTH' radical, has variants 咊 with the components' positions reversed, and 龢 with ⿕ 'FLUTE' replacing ⼝ 'MOUTH'.
See also
- Chinese family of scripts
- Adoption of Chinese literary culture
- Character amnesia
- Modern Chinese characters
- Chinese calligraphy
- Chinese numerals
- Chinese punctuation
- Eight Principles of Yong
- Stroke order
- Horizontal and vertical writing in East Asian scripts
- Chinese character forms
- Chinese character IT
- Chinese character meanings
- Chinese character orders
- Chinese character sounds
- Transcription into Chinese characters
- Romanisation of Chinese
Notes
- ↑ Baxter–Sagart (2014) reconstruction of Old Chinese.
- 1 2 3 Baxter's transcription for Middle Chinese.
- ↑ The standard Mandarin and Cantonese readings are given in Hanyu Pinyin and Jyutping, respectively. Japanese on'yomi readings are given in rōmaji.
- 1 2 3 Baxter (1992) reconstruction of Old Chinese.
- ↑ Some modern Chinese language works are still printed in vertical layout, but this is increasingly uncommon.
- ↑ Zev Handel lists:
- Sumerian cuneiform emerging c. 3200 BCE
- Egyptian hieroglyphs emerging c. 3100 BCE
- Chinese characters emerging c. 13th century BCE
- Maya script emerging around 2000 years before present
- ↑ There are exceptions to these general correspondences, including § Polysyllabic morphemes, syllables written with multiple characters, particles and affixes lacking strong independent meaning, and multiple syllables written with a single character.[8]
- ↑ This is possible in large part because the Chinese languages are highly analytic: the pronunciation of words is not altered depending on categories such as person, number, and there is no grammatical tense. Thus, phonetic and semantic information is not lost when single graphical characters are mapped to single morphemes.
- ↑ For the 500 most common characters, the proportion rises to 30%.[9]
- ↑ Baxter provides the reconstructed Old Chinese pronunciations of this pair as /*ɡ-ljuŋ/[29] and /*k-ljuŋ/[30] respectively.
- ↑ Numerous other readings exist for each compound; the ones given are among the earliest used that clearly illustrate a semantic distinction.
- ↑ Originally a pictogram of a vulva. The Shuowen Jiezi gives the origin of 也 as 女陰也; 'female yin [organ]'. By the 6th century BCE, the original definition had fallen into disuse. The use of the character in the definition itself is as a declarative sentence-final particle, and all appearances of the character in Classical texts from that time forward use it as a phonetic loan for the grammatical particle. In addition to being a Classical particle, in modern vernacular Chinese 也 has acquired a meaning of 'also'.
- 1 2 他 was originally the third-person personal pronoun regardless of gender or animacy in Chinese. The feminine-specific form 她 only emerged in the early 20th century, after the bulk of Japanese orthographic borrowing had already occurred.
- ↑ Compare 卢橘; 盧橘; lou4 gwat1, an unrelated name for the fruit which was eventually borrowed from Cantonese into English.
- ↑ In this case, the pronunciations have converged in Standard Chinese, but they have not in other varieties.
- ↑ 子 is reduced to a neutral tone in such compounds.
- ↑ Qiu 2000, pp. 132–133 provides archaeological evidence for this dating, in contrast to unsubstantiated claims dating the emergence of cursive anywhere from the Qin to the Eastern Han.
- ↑ Qiu 2000, pp. 140–141 mentions examples of neo-clerical with "strong overtones of cursive script" from the late Eastern Han.
- ↑ Liu is said to have taught Zhong Yao and Wang Xizhi.
- ↑ Wang is credited as such in essays by other calligraphers during the 6th and early 7th centuries, and most of his extant pieces are in modern cursive script.[97]
- ↑ Collectively the Standard Form of National Characters, which has been published online in full by Taiwan's Ministry of Education since 2017.[151]
- ↑ The character 们; 們 is a plural suffix particle for pronouns.
- ↑ Specifically, the Microsoft New Phonetic IME 2002a for traditional Chinese.
- ↑ Jiàndào is the pronunciation in Standard Chinese. Other varieties of Chinese have different pronunciations, such as:
- Southern Min (Taiwan): kiàm-tō (Pe̍h-ōe-jī / Tâi-uân Lô-má-jī Phing-im Hong-àn)[upper-alpha 16]
- Hakka Chinese (Sixian dialect): kiam-tho (Pha̍k-fa-sṳ) / giam-to (Taiwanese Hakka Romanisation System)[upper-alpha 17]
- Yue Chinese (Hong Kong): gim3-dou6[upper-alpha 18]
- Wu Chinese (Shanghainese): cie3-dau2 (Romanisation of Wu Chinese)[upper-alpha 19]
- Wu Chinese (Suzhou dialect): cie523-dau231[upper-alpha 20]
References
Citations
- ↑ 广西壮族自治区少数民族古籍整理出版规划领导小组 [Central Leadership Planning Group for the Organization and Publication of Early Written Materials of Guangxi Zhuang Ethnic Minority Autonomous Region], ed. (1989). Sawndip Sawdenj – Gǔ Zhuàng zì zìdiǎn 古壮字字典 [Dictionary of the Old Zhuang Script] (in Chinese) (2nd ed.). Nanning: Guangxi Nationalities Publishing House. ISBN 978-7-5363-0614-1.
- ↑ World Health Organization (2007). WHO International Standard Terminologies on Traditional Medicine in the Western Pacific Region. Manila: WHO Regional Office for the Western Pacific. hdl:10665/206952.
- ↑ Yun Xiao (2010). "Chinese in the USA". In Kim Potowski (ed.). Language Diversity in the USA. Cambridge: Cambridge University Press. pp. 81–95. doi:10.1017/CBO9780511779855.006. ISBN 978-0-521-74533-8.
- ↑ Handel 2019, p. 1.
- ↑ Elemy Liu, ed. (18 November 2009). "History of Chinese Writing Showed in the Museums". CCTV.com. Archived from the original on 21 November 2009. Retrieved 20 March 2010 – via Arts International.
- ↑ Routledge 2016, pp. 53–54.
- ↑ Hannas 1997.
- 1 2 3 4 Mair, Victor (2 August 2011). "Polysyllabic Characters in Chinese Writing". Language Log.
- ↑ Swofford, Mark (2010). "Chinese Characters with Multiple Pronunciations". Pinyin.info. Retrieved 4 July 2016.
- ↑ Norman 1988, pp. 67–69.
- ↑ Norman 1988, pp. 86–87.
- ↑ Qiu 2000, pp. 153–154.
- ↑ Norman 1988, pp. 195.
- 1 2 Qiu 2000, pp. 154.
- 1 2 Norman 1988, pp. 87.
- 1 2 Qiu 2000, pp. 44–45.
- ↑ Zhou 2003, pp. 61.
- ↑ Yip 2000, pp. 39–42.
- ↑ Qiu 2000, p. 46.
- ↑ Sampson & Chen 2013, p. 261.
- ↑ Boltz 1994, pp. 104–110.
- ↑ Sampson & Chen 2013, pp. 265–268.
- ↑ Yong & Peng 2008, pp. 20–21.
- ↑ Yong & Peng 2008, pp. 21.
- ↑ Boltz 1994, p. 169.
- 1 2 Gnanadesikan, Amalia E. (2011). The Writing Revolution: Cuneiform to the Internet. John Wiley & Sons. p. 61. ISBN 978-1-4443-5985-5.
- 1 2 Wright, David (2000). Translating Science: The Transmission of Western Chemistry Into Late Imperial China, 1840–1900. Brill. p. 211. ISBN 9789004117761.
- ↑ Norman 1988, pp. 88.
- ↑ Baxter 1992, p. 750.
- ↑ Baxter 1992, p. 810.
- ↑ Williams 2010.
- ↑ Baxter & Sagart 2014, p. 371.
- ↑ Norman 1988, pp. 94.
- ↑ Norman 1988, pp. 87–88.
- ↑ Norman 1988, p. 69.
- ↑ Baxter 1992, pp. 771, 772.
- ↑ Sampson & Chen 2013, pp. 260–261.
- ↑ Qiu 2013, pp. 102–108.
- ↑ Norman 1988, pp. 89.
- ↑ Qiu 2000, pp. 168.
- ↑ Yin 2007, pp. 97–100.
- ↑ Su 2014, pp. 102–111.
- ↑ Yang 2008, pp. 147–148.
- ↑ Tong, Xiuli; Liu, Phil D.; McBride-Chang, Catherine (2009). "Metalinguistic and subcharacter skills in Chinese literacy acquisition". In Clare Patricia Wood; Vincent Connelly (eds.). Contemporary Perspectives on Reading and Spelling. New York: Routledge. pp. 202–218. ISBN 978-0-415-49716-9. p. 203:
Often, the Chinese character can function as an independent unit in sentences, but sometimes it must be paired with another character or more to form a word. [...] Most words consist of two or more characters, and more than 80 per cent make use of lexical compounding of morphemes (Packard, 2000).
- ↑ Norman 1988, pp. 74–75.
- ↑ Wilkinson 2012, p. 22.
- ↑ Yip 2000, p. 18.
- ↑ Norman 1988, p. 58.
- ↑ Zhang, Shuya (2022). "Rethinking the *-s suffix in Old Chinese: with new evidence from Situ Rgyalrong" (PDF). Folia Linguistica. 56 (s43–s1): 129–167. doi:10.1515/flin-2022-2014. ISSN 0165-4004. S2CID 248002645 – via Academic Search Complete.
- ↑ Baxter 1992, pp. 315–317.
- 1 2 Baxter 1992, p. 315.
- ↑ Baxter 1992, p. 316.
- ↑ Baxter 1992, pp. 197, 305.
- 1 2 Baxter 1992, p. 218.
- ↑ Baxter 1992, p. 219.
- ↑ Norman 1988, p. 112.
- ↑ Norman 1988, pp. 155–156.
- ↑ Norman 1988, p. 74.
- ↑ Su 2014, p. 42.
- ↑ National Language Commission 2013.
- ↑ Handel 2019, p. 17,196.
- ↑ Yang Yuxin (2018). Unveiling and Activating the "Uncertain Heritage" of Chinese Knotting (PDF). The Asian Conference on Cultural Studies 2018. p. 3.
- ↑ Mair, Victor. "Prehistoric notation systems in Peru, with Chinese parallels". Language Log. Retrieved 31 July 2023.
- ↑ Sutherland, A. (15 March 2017). "Ancient Chinese Version Of Quipu -Tradition Of Tying Knots Dates Back To Antiquity". Ancient Pages. Retrieved 31 July 2023.
- ↑ Chan, Wing-tsit (1963). The Way of Lao Tzu (Tao Te Ching). The Bobbs-Merrill Company. p. 238. ISBN 0-02-320700-0. "Let the people again knot cords and use them (in place of writing)" – Explanatory parenthetical added by the translator.
- ↑ 系辞下 [Xi Ci II]. The Book of Changes 易經. Translated by Legge, James. 1899. Archived from the original on 24 September 2020 – via The Chinese Text Project.
In the highest antiquity, government was carried on successfully by the use of knotted cords (to preserve the memory of things). In subsequent ages the sages substituted for these written characters and bonds. By means of these (the doings of) all the officers could be regulated, and (the affairs of) all the people accurately examined.
- ↑ Yang, Lihui; An, Deming (2008). Handbook of Chinese Mythology. Oxford University Press. pp. 84–86. ISBN 978-0-19-533263-6.
- ↑ Jiang Yuxia, ed. (18 May 2007). "Carvings May Rewrite History of Chinese Characters". Xinhua Online. Archived from the original on 8 July 2007. Retrieved 19 May 2007."Chinese Writing '8,000 Years Old'". BBC News. 18 May 2007. Retrieved 17 November 2007.
- 1 2 Rincon, Paul (17 April 2003). "'Earliest Writing' Found in China". BBC News.
- ↑ Qiu 2000, p. 31.
- 1 2 3 4 Kern 2010, p. 1.
- ↑ Keightley 1978, p. xvi.
- ↑ Bagley, Robert (2004). "Anyang writing and the origin of the Chinese writing system". In Houston, Stephen (ed.). The First Writing: Script Invention as History and Process. Cambridge University Press. pp. 190–249. ISBN 978-0-521-83861-0.
- ↑ Boltz, William G. (1999). "Language and Writing". In Loewe, Michael; Shaughnessy, Edward L. (eds.). The Cambridge History of Ancient China: From the Origins of Civilization to 221 BC. Cambridge University Press. pp. 74–123. doi:10.1017/CHOL9780521470308.004. ISBN 978-0-521-47030-8. Retrieved 3 April 2019.
- ↑ Boltz 1986, p. 424.
- ↑ Keightley 1996.
- 1 2 Kern 2010, p. 2.
- ↑ Qiu 2000, pp. 63–64, 66, 86, 88–89, 104–107, 124.
- ↑ Qiu 2000, pp. 59–150.
- ↑ Chen Zhaorong (陳昭容) (2003). 秦系文字研究﹕从漢字史的角度考察 [Research on the Qín Writing System: Through the Lens of the History of Writing in China]. Institute of History and Philology Monograph (in Chinese). Academia Sinica. ISBN 978-9-576-71995-0.
- ↑ Qiu 2000, p. 104.
- ↑ Qiu 2000, pp. 59, 104–107.
- ↑ Qiu 2000, p. 119.
- ↑ Qiu 2000, p. 123.
- ↑ Qiu 2000, pp. 119, 123–124.
- ↑ Qiu 2000, p. 130.
- ↑ Qiu 2000, p. 121.
- ↑ Qiu 2000, pp. 131, 133.
- 1 2 3 4 5 Qiu 2000, p. 138.
- ↑ Qiu 2000, p. 131.
- 1 2 Qiu 2000, pp. 113, 139.
- 1 2 Qiu 2000, p. 139.
- ↑ Qiu 2000, p. 142.
- ↑ Qiu 2000, p. 140.
- 1 2 Qiu 2000, p. 143.
- ↑ Qiu 2000, p. 144.
- 1 2 Qiu 2000, p. 148.
- ↑ Qiu 2000, p. 145.
- ↑ Peking University 2004, pp. 148–152.
- ↑ Zhang 2013.
- ↑ Norman 1988, p. 86.
- ↑ Zhou 2003, p. 58.
- ↑ Routledge 2016, pp. 58–59.
- ↑ Li, Wendan (2009). Chinese Writing and Calligraphy. Honolulu: University of Hawai‘i Press. p. 70. ISBN 978-0-8248-3364-0.
- ↑ Qiu 2000, pp. 204–215, 373.
- ↑ Zhou 2003, p. 57-60, 63–65.
- ↑ Qiu 2000, pp. 297–300, 373.
- ↑ Nawar, Haytham (2020). "Transculturalism and Posthumanism". Language of Tomorrow: Towards a Transcultural Visual Communication System in a Posthuman Condition. Intellect. pp. 130–155. doi:10.2307/j.ctv36xvqb7.8. ISBN 978-1-78938-183-2. JSTOR j.ctv36xvqb7.
- ↑ Bai, Qianshen; Finlay, John (1993). "The World within a Square Inch: Modern Developments in Chinese Seal Carving". Yale University Art Gallery Bulletin: 49–61. ISSN 0084-3539. JSTOR 40514353.
- ↑ Li, Wendan (2009). Chinese Writing and Calligraphy. Honolulu: University of Hawai‘i Press. pp. 180–183. ISBN 978-0-8248-3364-0.
- ↑ Su 2014, p. 218.
- ↑ Li 2013, p. 62.
- ↑ Zhang 2006.
- ↑ National Language Commission 1997.
- ↑ Zhang 2016, p. 422.
- ↑ Su 2014, p. 222.
- ↑ Language Institute, Chinese Academy of Social Sciences 2020.
- ↑ Unicode Character Count V15.1, 2023, archived from the original on 9 October 2023, retrieved 28 November 2023
- ↑ Lunde, Ken (4 August 2022). "The GB 18030-2022 Standard". Medium. Retrieved 7 August 2022.
- ↑ Rabasa, José; Sato, Masayuki; Tortarolo, Edoardo; Woolf, Daniel, eds. (29 March 2012). The Oxford History of Historical Writing: Volume 3: 1400–1800. Vol. 3. Oxford University Press. p. 2. doi:10.1093/acprof:osobl/9780199219179.001.0001. ISBN 978-0-19-921917-9.
...East Asia had been among the first regions of the world to produce written records of the past. Well into modern times Chinese script, the common script across East Asia, served—with local adaptations and variations—as the normative medium of record-keeping and written historical narrative, as well as official communication. This was true, not only in China itself, but in Korea, Japan, and Vietnam.
- ↑ Handel 2019, p. 212.
- ↑ Handel 2019, pp. 64–65.
- ↑ "공문서 한글전용·초중등 한자교육 선택 고시 '합헌'(종합)" (in Korean). Maeil Kyungje. 24 November 2016. Archived from the original on 4 February 2022. Retrieved 4 February 2022.
- ↑ Coulmas 1991, pp. 122–129.
- ↑ Coulmas 1991, pp. 132–133.
- ↑ Coulmas 1991, pp. 129–132.
- ↑ "알고 싶은 한글". 국립국어원. National Institute of Korean Language. Retrieved 22 March 2018.
- 1 2 3 Fischer, Stephen Roger (4 April 2004). A History of Writing. Globalities. London: Reaktion Books. pp. 189–194. ISBN 1-86189-101-6. Retrieved 3 April 2009.
- ↑ Handel 2019, pp. 75–82.
- ↑ "Hanja Lesson 1: 大, 小, 中, 山, 門". How to Study Korean. Retrieved 9 March 2016.
- ↑ Choo, Miho; O'Grady, William (1996). Handbook of Korean Vocabulary: An Approach to Word Recognition and Comprehension. University of Hawaii Press. pp. ix. ISBN 0-8248-1815-6.
- 1 2 Hannas 1997, pp. 68–72.
- ↑ Byon, Andrew Sangpil (2017). Modern Korean Grammar: A Practical Guide. Taylor & Francis. pp. 3–18. ISBN 978-1-351-74129-3.
- ↑ Hannas 1997, p. 68.
- ↑ "북한의 한문교과서를 보다". Chosun NK (in Korean). 14 March 2014.
- ↑ Kim, Hye-jin 김혜진 (4 June 2001). "Bughan-ui hanjajeongchaeg – "hanja, 3000jakkaji baeudoe sseujineun malla"" 북한의 한자정책 – "漢字, 3000자까지 배우되 쓰지는 말라". Han Mun Love (in Korean). Chosun Ilbo. Archived from the original on 17 December 2014. Retrieved 21 November 2014.
- ↑ Hung, Eva; Wakabayashi, Judy (2005). Hung, Eva; Wakabayashi, Judy (eds.). Asian Translation Traditions. Manchester: St. Jerome Publishing. p. 18. ISBN 978-1-900-65078-6.
- ↑ Kiernan, Ben (2017). Viet Nam: A History from Earliest Times to the Present. Oxford University Press. p. 108. ISBN 978-0-19-062730-0.
- 1 2 Kornicki 2018, p. 63.
- ↑ DeFrancis 1977, p. 19.
- ↑ Clementin-Ojha, Catherine; Manguin, Pierre-Yves; Reid, Helen (2007). A Century in Asia: The History of the École Française D'Extrême-Orient, 1898–2006. Editions Didier Millet. p. 141. ISBN 978-9-81415-597-7.
- ↑ Handel 2019, p. 135.
- ↑ Shih, Chih-yu; Manomaivibool, Prapin; Marwah, Reena (2018). China Studies In South And Southeast Asia: Between Pro-china And Objectivism. World Scientific Publishing Company. p. 117. ISBN 978-9-81323-526-7.
- ↑ Coulmas 1991, pp. 113–115.
- ↑ DeFrancis 1977, pp. 75–219.
- 1 2 Zhou, Youguang (1991). "The Family of Chinese Character-Type Scripts (Twenty Members and Four Stages of Development)". Sino-Platonic Papers. 28. Retrieved 7 June 2011 – via www.sino-platonic.org.
- ↑ Tang, Weiping 唐未平, Guǎngxī zhuàngzú rén wénzì shǐyòng xiànzhuàng jí wénzì shèhuì shēngwàng diàochá yánjiū—yǐ tiányáng, tián dōng, dōng lán sān xiàn wéi lì 广西壮族人文字使用现状及文字社会声望调查研究—以田阳、田东、东兰三县为例 [A Survey and Study on the Using Status and Attitude About the Writing Systems Being Used in Zhuang—Take Tianyang, Tiandong and Donglan for Examples] (in Chinese) – via doc88.com
- ↑ Gulick, John (1870). "On the Best Method of Representing the Unaspirated Mutes of the Mandarin Dialect". The Chinese Recorder and Missionary Journal. 3: 153–155 – via Google Books.
- ↑ 国务院关于公布《通用规范汉字表》的通知 [Notice of the State Council on the publication of the "General Standard Chinese Character List"]. Gov.cn (in Chinese). State Council of the People's Republic of China. 5 June 2013.
- ↑ Chángyòng zì zìxíng biǎo: Èrlínglíngqī nián chóng pái běn: Fù yuè pǔ zìyīn jí yīngwén jiěshì 常用字字形表: 二零零七年重排本 : 附粤普字音及英文解釋 [Commonly used character glyph table: 2007 rearranged edition with Cantonese and Mandarin phonetic pronunciations and English explanations] (in Chinese). Hong Kong Education Bureau. 2012. ISBN 9789888123933.
- 1 2 "異體字字典". Taiwan Ministry of Education (in Chinese). 2017.
- ↑ Chángyòng guózì biāo zhǔnzì tǐbiǎo 常用國字標準字體表 [Chart of Standard Forms of Common National Characters] (in Chinese). Taipei: Zhengzhong shuju. 1983. ISBN 9789570906646.
- ↑ Lunde 2008, pp. 81–82.
- ↑ "Kaitei jōyōkanji-hyō, 30-nichi ni naikaku kokuji kakugi de seishiki kettei" 改定常用漢字表、30日に内閣告示 閣議で正式決定 [The amended list of jōyō kanji receives cabinet notice on 30th: to be officially confirmed in cabinet meeting.] (in Japanese). Nihon Keizai Shimbun. 24 November 2010. Archived from the original on 3 March 2016. Retrieved 1 February 2015.
- 1 2 Lunde 2008, pp. 84.
- ↑ "Source Han Serif". Typekit. Retrieved 3 October 2023.
- ↑ Yen, Yuehping (2005). Calligraphy and Power in Contemporary Chinese Society. London: Routledge. ISBN 0-415-31753-3.
- ↑ Chen 1999, pp. 153.
- ↑ Lü Bolin (呂柏林). 简化字的昨天、今天和明天 [Simplified Chinese characters for yesterday, today and tomorrow]. 乾坤再造在中华 (in Chinese). Archived from the original on 14 July 2011.
- ↑ Chen 1999, pp. 150–153.
- ↑ Chen 1999, pp. 151.
- ↑ Chen 1999, pp. 182–186.
- ↑ Chen 1999, pp. 154.
- ↑ Ramsey 1987, p. 147.
- ↑ Chen 1999, pp. 155–156.
- ↑ "Guówùyuàn guānyú gōngbù "Tōngyòng guīfàn hànzì biǎo" de tōngzhī" 国务院关于公布《通用规范汉字表》的通知 [State Council announcement of the Table of General Standard Chinese Characters] (in Chinese). Central People's Government of the People's Republic of China. 5 June 2013. Retrieved 8 November 2023.
- ↑ Lunde 2008, pp. 7, 86.
- ↑ "China's HSK Language Test to be Overhauled for the First 11 years". The Beijinger (blog). 3 April 2021.
- ↑ Zhao Xiaoxie (赵晓霞) (9 April 2021). 《国际中文教育中文水平等级标准》来了 汉语水平考试会有啥变化 [HSK 3.0 is here. What changes will there be?] (in Chinese). People's Daily Overseas Edition. Archived from the original on 20 May 2021. Retrieved 20 May 2021.
日前,《国际中文教育中文水平等级标准》(GF0025-2021)(下称《标准》)由教育部、国家语言文字工作委员会发布,作为国家语委语言文字规范自2021年7月1日起正式实施。......汉语水平考试(HSK)自1984年开创以来已走过37年,经历了基础、初中等、高等"3等11级"的HSK1.0和"一级到六级"6个级别的HSK2.0两个阶段,即将迎来"三等九级"的HSK3.0新阶段。
- ↑ "What is Chinese Proficiency Test?". China's University and College Admission System. Archived from the original on 22 December 2015.
- ↑ Chen 1999, pp. 161.
- ↑ Chia Shih Yar (谢世涯). Xīnjiāpō yǔ zhōngguó tiáozhěng jiǎntǐzì de píng zhì 新加坡与中国调整简体字的评骘 [A Comparative Study of the Revision of Simplified Chinese Characters Proposed by Singapore and China]. Paper presented at The International Conference on Culture of Chinese Character. Convened by Beijing Normal University and Liaoning People Publishing House. Dandong, Liaoning, China. 9-11 Nov 1998 (in Chinese) – via huayuqiao.org.
- ↑ "About CNS – Current Status – CNS11643 中文全字庫". Taiwan Ministry of Digital Affairs.
- ↑ "Taiwan Benchmarks for the Chinese Language". National Academy for Educational Research.
The TBCL sets out seven levels of Chinese language proficiency in the five skills: listening, speaking, reading, writing and translating. It also includes lists which contains 3,100 Chinese characters, 14,425 words, and 496 grammar points for learners of level 1 to 5.
- ↑ Lin Qinglong (林慶隆) (1 August 2020). Qiǎncíyòng 'Jù' : Táiwān huáyǔ wén nénglì dìyī tàobiāozhǔn 遣辭用「據」:臺灣華語文能力第一套標準 [The First Set of Standards for Chinese Language Proficiency in Taiwan] (PDF) (in Chinese). Taipei: National Academy for Educational Research. ISBN 9789865460082. Archived (PDF) from the original on 20 May 2021.
本字表各級收錄字數:第1級246個字、第2級258個字、第3級297個字;第4級499個字、第5級600個字;第6級600個字、第7級600個字,共計3,100個字。
- ↑ Hua, Vanessa (8 May 2006). "For Students of Chinese, Politics Fill the Characters / Traditionalists Bemoan Rise of Simplified Writing System Promoted by Communist Government to Improve Literacy". SFGATE. Retrieved 28 February 2018.
- ↑ Kane, Mathew (November–December 2012). "Chinese Character Usage in New York City" (PDF). The ATA Chronicle. pp. 20–23. Archived from the original (PDF) on 15 December 2018. Retrieved 22 July 2019.
- ↑ "What are the Jinmeiyō Kanji?". sci.lang.japan FAQ. Retrieved 11 November 2015.
- ↑ "Jinmeiyōkanji ni 「渾」 Tsuika shihō handan o uke Hōmushō kaisei koseki-hō shikōkisoku o shikō, kei 863-ji ni" 人名用漢字に「渾」追加 司法判断を受け法務省 改正戸籍法施行規則を施行、計863字に. The Nikkei (in Japanese). 25 September 2017.
- ↑ Mair, Victor H. "Danger + Opportunity ≠ Crisis: How A Misunderstanding About Chinese Characters Has Led Many Astray". Pinyin.info. Retrieved 20 August 2010.
- ↑ Kern, Martin (2002). "Methodological Reflections on the Analysis of Textual Variants and the Modes of Manuscript Production in Early China". Journal of East Asian Archaeology. 4 (1): 143–181. doi:10.1163/156852302322454521. ISSN 1387-6813.
- ↑ Wu Kuang-Ch'ing (吳光淸) (1943). "Ming Printing and Printers". Harvard Journal of Asiatic Studies. 7 (3): 229–232, 255–256. doi:10.2307/2718015. ISSN 0073-0548. JSTOR 2718015.
- ↑ Montucci (1817). Urh-Chĭh-Tsze-Tëen-Se-Yĭn-Pe-Keáou; Being a Parallel Drawn Between the Two Intended Chinese Dictionaries; by The Rev. Robert Morrison, and Antonio Montucci, Ll. D.
- ↑ Matthews, Stephen; Yip, Virginia (2011). Cantonese: A Comprehensive Grammar (2nd ed.). London: Routledge. p. 445. ISBN 978-0-415-47131-2.
- ↑ Norman 1988, pp. 8–9.
- ↑ "漢字の現在:幽霊文字からキョンシー文字へ?" [From Ghost Character to Vampire Character?]. dictionary.sanseido-publ.co.jp (in Japanese). Retrieved 24 January 2015.
- ↑ Su 2014, p. 183.
- ↑ Yong & Peng 2008, pp. 145, 400–401.
- ↑ Da, Jun (2010). "Welcome". Chinese Text Computing.
- ↑ Norman 1988, p. 73.
- ↑ Heisig, James W. (2013). Remembering the kanji. Honolulu: University of Hawaiʻi Press. ISBN 978-0-8248-3669-6. Retrieved 12 February 2022.
- ↑ Koichi (6 April 2011). "The Ultimate Kanji Test: Kanji Kentei". Tofugu. Retrieved 11 November 2015.
- ↑ "Summary of the deliberation results of the Korean Language Council on the scope of Chinese characters for personal use". National Academy of the Korean Language (in Korean). 1991. Archived from the original on 19 March 2016.
- ↑ "'인명용(人名用)' 한자 5761→8142자로 대폭 확대". Chosun Ilbo (in Korean). 20 October 2014. Retrieved 23 August 2017.
- ↑ "Creating New Chinese Characters". pages.ucsd.edu.
- ↑ Su 2014, p. 47.
- ↑ Su 2014, p. 51.
- ↑ "UAX #38: Unicode Han Database (Unihan)".
- 1 2 3 4 5 Zhou 2003, p. 72.
- ↑ Qiu 2000, p. 48.
- 1 2 3 4 5 Yip 2000, p. 19.
- ↑ Pulleyblank 1984, p. 139.
- 1 2 Zhou 2003, p. 73.
- ↑ Yong & Peng 2008, pp. 198–199.
- ↑ Yong & Peng 2008, p. 199.
- ↑ Yong & Peng 2008, p. 170.
- ↑ Yong & Peng 2008, p. 289.
- ↑ Yong & Peng 2008, p. 295.
- ↑ Yong & Peng 2008, p. 276.
- ↑ Wilkinson 2012, p. 46.
- ↑ ""Yìtǐzì zìdiǎn" wǎng lù bǎn shuōmíng" 《異體字字典》網路版說明. dict.variants.moe.edu.tw (in Chinese). Archived from the original on 17 March 2009. Official website for "The Dictionary of Chinese Variant Form", Introductory page
- ↑ "大漢和辞典デジタル版 – 株式会社大修館書店". www.taishukan.co.jp (in Japanese). Retrieved 1 November 2023.
- ↑ "World's Biggest Chinese Character Dictionary Nearly Complete". english.chosun.com. Retrieved 1 November 2023.
- ↑ Sugawara Yoshizō (菅原義三) (ed.). 国字の字典 [Dictionary of National Characters] (in Japanese). Tōkyōdō Shuppan. ISBN 978-4-490-10279-6.
- ↑ Phan, John (2013). "Chữ Nôm and the Taming of the South: A Bilingual Defense for Vernacular Writing in the Chỉ Nam Ngọc Âm Giải Nghĩa". Journal of Vietnamese Studies. Oakland, California: University of California Press. 8 (1): 1. doi:10.1525/vs.2013.8.1.1. JSTOR 10.1525/vs.2013.8.1.1.
Example lexemes
- ↑ "日". Hanyu Da Zidian (in Chinese). 1989. p. 1588."月". Hanyu Da Zidian (in Chinese). 1989. p. 2188."木". Hanyu Da Zidian (in Chinese). 1989. p. 1231.
- ↑ "高". Hanyu Da Zidian (in Chinese). 1989. p. 4893."畐". Hanyu Da Zidian (in Chinese). 1989. p. 2710.
- ↑ "明". Hanyu Da Zidian (in Chinese). 1989. p. 1599."萌". Hanyu Da Zidian (in Chinese). 1989. p. 3447."明白". Concised Mandarin Chinese Dictionary (in Chinese). Taiwan Ministry of Education. 2021."好". Hanyu Da Zidian (in Chinese). 1989. p. 1101.
- ↑ "砼". Hanyu Da Zidian (in Chinese). 1989. p. 2594.
- ↑ "琵". Dictionary of Chinese Character Variants (in Chinese). Taiwan Ministry of Education. "琶". Dictionary of Chinese Character Variants (in Chinese). Taiwan Ministry of Education.
- ↑ "說話". Revised Mandarin Chinese Dictionary (in Chinese). Taiwan Ministry of Education. 2021.
- ↑ "鴨子". Revised Mandarin Chinese Dictionary (in Chinese). Taiwan Ministry of Education. 2021.
- ↑ "桑". Revised Mandarin Chinese Dictionary (in Chinese). Taiwan Ministry of Education. 2021.
- ↑ "來". Hanyu Da Zidian (in Chinese). 1989. p. 175."雲". Hanyu Da Zidian (in Chinese). 1989. p. 4323.
- ↑ "囍". Education Encyclopedia (in Chinese).
- ↑ Li, Na 李娜; Chen, Shuangxin 陈双新 (12 August 2018). ""廿"该怎么读" [How to pronounce "廿"]. news.gmw.cn (in Chinese). Guangming Online. Retrieved 31 October 2023.
- ↑ ""圕" zì zěnme niàn? Shénme yìsi? Shéi zào de?" "圕"字怎么念?什么意思?谁造的?. Singtao Net (in Chinese). 21 April 2006. Archived from the original on 3 October 2011.""圕" zì zì zěnme niàn? Tái jiàoyù bùmén fùzé rén bèi kǎo dào" "圕"字字怎么念?台教育部门负责人被考倒. Xinhua News Agency (in Chinese). 20 March 2009. Archived from the original on 25 March 2009.
- ↑ It is found, for instance, on p. 707 of A Chinese–English Dictionary, (Revised Edition) Foreign Language Teaching and Research Press, Beijing, 1995. ISBN 978-7-5600-0739-7.
- ↑ "隑". International Encoded Han Character and Variants Database. Academica Sinica. Retrieved 31 October 2023.
- ↑ "㓾". Dictionary of Frequently-Used Taiwan Hakka. Taiwan Ministry of Education.
- ↑ "劍". Dictionary of Frequently-Used Taiwan Minnan. Taiwan Ministry of Education."道". Dictionary of Frequently-Used Taiwan Minnan. Taiwan Ministry of Education.
- ↑ "劍". Dictionary of Frequently-Used Taiwan Hakka. Taiwan Ministry of Education."道". Dictionary of Frequently-Used Taiwan Hakka. Taiwan Ministry of Education.
- ↑ 劍. 香港小學習字表 [Hong Kong Elementary School Character Study Guide].道. 香港小學習字表 [Hong Kong Elementary School Character Study Guide].
- ↑ "劍". Shanghai Wu Mini-Dictionary."道". Shanghai Wu Mini-Dictionary.
- ↑ "劍". Suzhou Wu Mini-Dictionary."道". Suzhou Wu Mini-Dictionary.
Works cited
- Baxter, William H. (1992). A Handbook of Old Chinese Phonology. Berlin: Mouton de Gruyter. ISBN 978-3-110-12324-1.
- ———; Sagart, Laurent (2014). Old Chinese: A New Reconstruction. Oxford University Press. ISBN 978-0-199-94537-5.
- Boltz, William G. (1986). "Early Chinese Writing". World Archaeology. 17 (3): 420–436. doi:10.1080/00438243.1986.9979980. JSTOR 124705.
- ——— (1994). The Origin and Early Development of the Chinese Writing System. New Haven: American Oriental Society. ISBN 978-0-940-49078-9.
- Chan, Sin-Wai, ed. (2016). The Routledge Encyclopedia of the Chinese Language. Routledge. ISBN 978-1-317-38249-2.
- Chen Ping (陳平) (1999). Modern Chinese: History and Sociolinguistics (4th ed.). Cambridge University Press. ISBN 978-0-521-64572-0.
- Coulmas, Florian (1991). The Writing Systems of the World. Blackwell. ISBN 978-0-631-18028-9.
- DeFrancis, John (1977). Colonialism and Language Policy in Viet Nam. Mouton. ISBN 978-9-027-97643-7.
- Demattè, Paola (2022). The Origins of Chinese Writing. Oxford University Press. ISBN 978-0-197-63576-6.
- Handel, Zev (2019). Sinography: The Borrowing and Adaptation of the Chinese Script. Brill. ISBN 978-9-004-35222-3. S2CID 189494805. Retrieved 1 November 2023.
- Hannas, William C. (1997). Asia's Orthographic Dilemma. University of Hawaiʻi Press. ISBN 978-0-824-81892-0.
- Keightley, David (1978). Sources of Shang History: The Oracle-Bone Inscriptions of Bronze-Age China. Berkeley: University of California Press. ISBN 978-0-520-02969-9.
- Kornicki, Peter (2018). Languages, Scripts, and Chinese Texts in East Asia. Oxford University Press. ISBN 978-0-192-51869-9.
- ——— (1996). "Art, Ancestors, and the Origins of Writing in China". Representations. 56 (56): 68–95. doi:10.1525/rep.1996.56.1.99p0343q. JSTOR 2928708.
- Kern, Martin (2010). "Early Chinese Literature, Beginnings through Western Han". In Owen, Stephen (ed.). The Cambridge History of Chinese Literature, vol. 1: To 1375. Cambridge University Press. pp. 1–115. ISBN 978-0-521-85558-7.
- Language Institute, Chinese Academy of Social Sciences (2020). 新华字典 [Xinhua Dictionary] (in Chinese) (12th ed.). Beijing: Shangwu yinshuguan (The Commercial Press). ISBN 978-7-100-17093-2.
- Li Dasui (李大遂) (2013). 简明实用汉字学 [Concise and Practical Chinese Characters] (in Chinese) (3rd ed.). Peking University Press. ISBN 978-7-301-21958-4.
- 信息处理用GB13000.1字符集汉字部件规范 [Chinese Character Component Standard of GB13000.1 Character Set for Information Processing] (PDF) (in Chinese), Beijing: National Language Commission of China, 1997
- Chinese Ministry of Education National Language Commission (2013). 2012年中国语言生活状况报告 [2012 Report on Language Life in China] (in Chinese). Beijing: Shangwu yinshuguan (The Commercial Press).
- Lunde, Ken (2008). CJKV Information Processing (2nd ed.). O'Reilly Media. ISBN 978-0-596-51447-1.
- Norman, Jerry (1988). Chinese. Cambridge University Press. ISBN 978-0-521-29653-3.
- Peking University Modern Chinese Language Teaching and Research Office (2004). 现代汉语 [Modern Chinese] (in Chinese). Shangwu yinshuguan (The Commercial Press). ISBN 978-7-100-00940-9.
- Pulleyblank, Edwin G. (1984). Middle Chinese: A Study in Historical Phonology. Vancouver: University of British Columbia Press. ISBN 978-0-774-80192-8.
- Qiu Xigui (裘锡圭) (2000) [1988]. Chinese Writing. Translated by Gilbert L. Mattos; Norman, Jerry. Berkeley: Society for the Study of Early China and The Institute of East Asian Studies, University of California. ISBN 978-1-557-29071-7.
- ——— (2013). 文字学概要 [Chinese Writing] (in Chinese) (2nd ed.). Beijing: Shangwu yinshuguan (The Commercial Press). ISBN 978-7-100-09369-9.
- Ramsey, S. Robert (1987). The Languages of China. Princeton University Press. ISBN 978-0-691-01468-5.
- Sampson, Geoffrey; Chen, Zhiqun (2013). "The reality of compound ideographs". Journal of Chinese Linguistics. 41 (2): 255–272. JSTOR 23754815.
- Su Peicheng (苏培成) (2014). 现代汉字学纲要 [Essentials of Modern Chinese Characters] (in Chinese) (3rd ed.). Beijing: Shangwu yinshuguan (The Commercial Press). ISBN 978-7-100-10440-1.
- Unicode Standard, Version 15.1.0, Mountain View, CA: Unicode Consortium, 2023, ISBN 978-1-936-21332-0
- Wilkinson, Endymion (2012). Chinese History: A New Manual. Harvard-Yenching Institute Monograph Series. Cambridge, MA: Harvard-Yenching Institute; Harvard University Asia Center. ISBN 978-0-674-06715-8.
- Williams, Clay H. (2010). Semantic vs. phonetic decoding strategies in non-native readers of Chinese (PDF) (Ph.D. thesis). University of Arizona Graduate College of Second Language Acquisition & Teaching. hdl:10150/195163. Archived (PDF) from the original on 9 October 2022.
- Yang Runlu (杨润陆) (2008). 现代汉字学 [Modern Chinese Characters] (in Chinese). Beijing Normal University Press. ISBN 978-7-303-09437-0.
- Yin Jiming (殷寄明); et al. (2007). 现代汉语文字学 [Modern Chinese Writing] (in Chinese). Shanghai: Fudan daxue chubanshe (Fudan University Press). ISBN 978-7-309-05525-2.
- Yip, Po-ching (2000). The Chinese Lexicon: A Comprehensive Survey. Psychology Press. ISBN 978-0-415-15174-0.
- Yong, Heming; Peng, Jing (2008). Chinese Lexicography: A History from 1046 BC to AD 1911. Oxford University Press. ISBN 978-0-191-56167-2.
- Zhang Xiaoheng (张小衡) (2006). 字形的 '号制' '点制' 与 '米制' [The Number, Point and Metric Systems of Font Size]. 计算机工程与应用 [Computer Engineering and Applications] (in Chinese). 42 (10): 175–177, 215.
- ———; Li Xiaotong (李笑通) (2013). 一二三笔顺检字手册 [Handbook of the YES Sorting Method] (in Chinese). Beijing: Yuwen chubanshe (The Language Press). ISBN 978-7-802-41670-3.
- ——— (2016). "Computational Linguistics". The Routledge Encyclopedia of the Chinese Language. Routledge. pp. 420–437. ISBN 978-0-415-53970-8.
- Zhou Youguang (周有光) (2003). The Historical Evolution of Chinese Languages and Scripts 中国语文的时代演进 (in English and Chinese). Translated by Zhang Liqing (张立青). Columbus: National East Asian Languages Resource Center, Ohio State University. ISBN 978-0-87415-349-1.
![]() This article incorporates text from Chinese Recorder and Missionary Journal, vol. 3, a publication from 1871, now in the public domain in the United States.
This article incorporates text from Chinese Recorder and Missionary Journal, vol. 3, a publication from 1871, now in the public domain in the United States.
Further reading
- Demattè, Paola (2022). The Origins of Chinese writing. Oxford University Press. ISBN 978-0-197-63576-6.
- Galambos, Imre (2006). Orthography of Early Chinese Writing: Evidence from Newly Excavated Manuscripts (PDF). Budapest: Eötvös Loránd University. ISBN 978-9-634-63811-7. Archived (PDF) from the original on 15 May 2012.
Works of historical interest
- Medhurst, Walter Henry (1842). Chinese and English dictionary. Parapattan: Walter Henry Medhurst.
- Williams, Samuel Wells (1842). Easy lessons in Chinese. Office of the Chinese Repository.
- Edkins, Joseph (1876). Introduction to the study of the Chinese characters. Trübner.
- Chalmers, John (1882). An account of the structure of Chinese characters under 300 primary forms. Trübner.
- Giles, Herbert Allen (1892). A Chinese–English dictionary. Vol. 1. B. Quaritch.
- Chinese and English dictionary. American Tract Society. 1893.
- Poletti, P. (1896). A Chinese and English dictionary. American Presbyterian Mission Press.
- Soothill, William Edward (1900). The student's four thousand characters and general pocket dictionary (2nd ed.). American Presbyterian Mission Press.
- Tai Tung (戴侗) (1954). The Six Scripts. Translated by Hopkins, L.C. Cambridge University Press. ISBN 978-1-107-60515-2.
External links
Online references and databases
- Unihan Database – Official Unicode site on Chinese characters and Han unification, with reference glyphs, readings, and meanings for all characters encoded in the standard
- Chinese Text Project Dictionary – Comprehensive character dictionary, including data for all Chinese characters within Unicode, and exemplary examples of use in Classical Chinese texts
- zi.tools – Character lookup by component description, character etymology, phonology, orthography, and dictionary
- Chinese Etymology by Richard Sears
- Chinese text computing – Statistics regarding the use of Chinese characters, by Jun Da
Character history and construction
- Excerpt from Visible Speech: The Diverse Oneness of Writing Systems by John DeFrancis, published in 1989 by University of Hawai‘i Press, reproduced with permission
- Evolution of Chinese Characters at Omniglot
| Varieties |
| ||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Standard forms | |||||||||||||||||||||||||||||||||||||||
| Phonology | |||||||||||||||||||||||||||||||||||||||
| Grammar | |||||||||||||||||||||||||||||||||||||||
| Idioms | |||||||||||||||||||||||||||||||||||||||
| Input | |||||||||||||||||||||||||||||||||||||||
| History | |||||||||||||||||||||||||||||||||||||||
| Literary forms |
| ||||||||||||||||||||||||||||||||||||||
| Scripts |
| ||||||||||||||||||||||||||||||||||||||